
Pages
- NodeTools: Node.JS Stack
- Quick Start To NodeTools
- TrapCSS: NodeTools Tutorial
- TrapCSS 2: Advanced NodeTools
- Web Development With NodeTools
- Babel: When Open Source Is Not Free Sofware
- Discussion for NodeTools
Stack
Web Software
Misc
TrapCSS2: Advanced NodeTools
In the previous part, we looked at the first steps in creating a new package with NodeTools stack. During the initialisation process with mnp, we were asked some questions like if we wanted to compile the package, if a binary should be added and whether GitHub wiki should be created. We answered yes to all three questions, so let's get on with the second part of the tutorial.

At the end, we'll also look how to incorporate TrapCSS into another package with StdLib strategy: we'll compile a file called stdlib.js for a static website generator Splendid that will statically link to trapcss, meaning that they will be distributed together. This will allow to reduce the total number of dependencies in the target package and make it more appealing to users.

Welcome Closure
Prior to NodeTools, the industry standard was to simply transpile source code with Babel, or not use modules at all and avoid transpilation step altogether. The first option is not good because Babel is a package with 250+ dependencies that jam our node_modules, and also because for years it's been disparaging professional software engineering values that are in core of NodeTools, such as respect for JSDoc, as can be read in the Babel: When Open Source Is Not Free Sofware article. The second option is not applicable either as I believe in embracing innovation and keeping up with the newest technological advances to be able to be productive and remain competent and competitive.
Because NearForm, the largest contributor to Node.JS with labour resource of over 100 people, extorted back-end engineers into using Babel by not implementing ECMA modules since 2015, the actual state of art of modern package making is pretty sad. Those working on Babel took the advantage of that forced downloads count to call their buggy product a compiler, which is not true. It's popular only because people had no choice rather because it's exceptional in any way. A compiler is a sophisticated piece of software so there must be something special about a program to be called this name (rather than a transpiler). Closure Compiler is software that will check types and perform advanced passes like peep-hole optimisation and function call folding, therefore it really deserves this title.Up until NodeTools, there were 4 ways to create Node.JS packages:
- old-school, by keeping module.exports and not taking advantage of modules' syntax which is one of the best features of JavaScript;
- alternative, that included an additional bundle up step, with such software as rollup and webpack;
- TypeScript, which is a corporate paradigm that has swept the world due to the lack of professional tools that could compete with it to provide good routines for working with types;
- Babel, the mass-mentality industry pattern that has no respect for its users, whose authors self-proclaimed themselves leaders of the sector while failing miserably to meet essential requirements for a transpiler.
NodeTools is a new, indie replacement to all these methods that allows to leave them behind and focus on JS coding. We provide the most light-weight, pure JavaScript solution that would allow to develop professional packages and keep independent from 3rd party software that dictates how you should work and what your code should look like. The developer and her freedom is our top priority. For example, there's literally no config for compiling you packages, and all annotations are based on the open JSDoc standard. You can still choose the language output (such as ECMA2015-2019) and control other options like pretty printing via CLI arguments. NodeTools is the only methodology that starts to use Closure Compiler for packages, and it takes Node.JS software development to the next level.
Installation
Closure Compiler is developed by Google. It's used for mission-critical internal projects, that are not based on TypeScript. It's a Java program of the size of 10MB that can be installed once on the system, and using advanced optimisations, can put the source code, as well as all liked dependencies into a single executable file. In other words, it provides static linking for libraries into our generated code. Type checking now becomes the final stage of the development process that provides insight into small inaccuracies in our types, instead of forcing us to think in terms of types, like in TypeScript.
To use the compiler, you'll need Java on your machine. If you're working on Windows, you can just install it from the official website and it'll be working fine. On a Mac, I had to add the following line to my ~/.bash_profile.export JAVA_HOME=/Library/Internet\ Plug-Ins\JavaAppletPlugin.plugin/Contents/HomeIf you're using zsh, also add source ~/.bash_profile to your ~/.zshrc. Then we're going to install google-closure-compiler-java into the home folder:
cd ~
yarn|npm init # we want to save deps in package.json
yarn add google-closure-compiler-javaYour distribution will be installed in the ~/node_modules directory. On top of the compiler itself, the actual package that executes the process, is called Depack. It's made possible to compile Node.JS package for the first time, since it wasn't possible before as when trying to compile back-end software with Closure, it would throw errors since it couldn't recognise internal Node API, such as fs, stream, etc. Depack fixes this by creating mock folders in your node_modules, such as node_modules/fs/index.js, node_modules/fs/package.json that simply destructure the global API annotated via externs to enable type checking. We've implemented the externs for Node 8 API, which should also work with later versions.
// node_modules/child_process/index.js
/* a mock of child process built-in */
export default child_process
export const {
ChildProcess,
exec,
execFile,
execFileSync,
execSync,
fork,
spawn,
spawnSync,
} = child_process// node_modules/child_process/package.json
{
"name": "child_process",
"main": "index.js"
}You can use nightly versions of the compiler, if you want, by looking up the last version with yarn npm info google-closure-compiler-java and setting the exact version, e.g., yarn npm iadd google-closure-compiler-java@20200201.0.0-nightly. This can help if there are occasional bugs in the compiler, e.g., the January 2020 version has broken destructuring, so you need to use the nightly build like the one I've just mentioned. There's a list of bugs in the compiler in the Depack wiki.
Closure is written in Java. You can fork their project and study how it works. There's a lot of useful information on the Wiki, especially in the types section. It might seem complex at first, but I managed to fix certain issues with PRs by only studying the source code for a few days. A compiler is based on AST passes, where you can manipulate nodes. There's also a JSDoc parser, and an inner project for JS source map consumption/generation. When you make a change, you build the compiler locally. Then you can set the GOOGLE_CLOSURE_COMPILER env variable with the path to your target JAR, which will then be used by NodeTools.Advantages
Some might say that we're still tied up to the compiler, but it's much better than Babel and TypeScript, because:
- You don't need to install 250 dependencies just for your modules' syntax via Babel.
- The bin size is 10mb instead of 50mb of TypeScript.
- You can statically link packages like in proper software engineering.
- Compiler will produce type hints for you that are useful to polish your programs, but don't lock you into a completely different language which TS is.
- It's meant for pure JavaScript development which is great.
- Its advanced optimisation obfuscates code so that you can send it to your clients with a bit more security for your intellectual property.
- You can compile complex back-end applications into a single JS file, for example, we created Idio which is a Koa server with essential middleware that only has 2 dependencies (mime-db and text-decoding which are databases for processing encoded data). Without compilation, Idio would have to download around 130 external dependencies.
- It's maintained by Google themselves by top-level software engineers who know compiler theory, so you can rely on compilation results.
- You don't have to compile, and simple transpilation is also possible without Closure.
- You can keep the source code of your larger packages non-compiled, but instead compile only its dependencies into a file called StdLib.
Additionally, another reason to learn about compiler and externs, is because the highest paid Software Engineering positions are for Clojure language, around $140k per year in the US. When you're working on Clojure projects, you'll be writing your front-end in ClojureScript, that produces JavaScript compatible with Closure Compiler, so you'll need to understand how externs work. If you learn it via NodeTools today, you'll be prepared to become one of the highest-paid developers in the world if you decide to specialise in Clojure at some point.
Web Bundling
NodeTools is a holistic package development methodology. The compiler works together with all other tools, such as Typal, that allows to maintain a single source of truth for your types and generate externs for the compiler, Documentary that can embed and interlink such type information in documentation of packages including wikis, and Zoroaster that provides API to test forks as well as letting you test your target compiled code, instead of only source code, which is an absolute must when taking advantage of the advanced compilation mode.
The primary realm of our stack is Node.JS package development, however with Depack you can also develop and compile web-bundles, as there's also support for JSX syntax in ÀLaMode. It's based on regexes, but we've managed to create many nice widgets for the web with it. We'll be advertising the web stack features later on. We hope that the tools that we provide in only 10 node_modules folders, will really allow to have a breath of fresh air in this stale-air environment where people adapt to paradigms, instead of using such powerful language as JavaScript to their maximum advantage.You can read about compiling front-end JavaScript code in the Web Development With NodeTools article.

Compiling Libraries
Let's get down to business. Advanced compilation means that our comments are going to be stripped off the source code, so that all type information is lost. It's possible to preserve all comments, however this is a new feature of the compiler, and will keep ALL comments which might be undesirable. We'll be compiling our API, so the strategy is the following:
- to compile the source code into a file that exports API methods,
- to import those API methods from another file that wraps them in JSDoc.
Templates
The entry point for the compiler is src/depack.js, which imports the method from the source code and exports it via CommonJS standard. It also imports externs so that Closure will understand our types:
import '../types/externs'
import trapcss from './'
/*!
* trapcss: Removes unused selectors from CSS files to achieve
* maximum optimisation. Can be used as an API function or with CLI.
*
* Copyright (C) 2020 Art Deco Code Limited
*
* This program is free software: you can redistribute it and/or modify
* it under the terms of the GNU Affero General Public License as
* published by the Free Software Foundation, either version 3 of the
* License, or (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU Affero General Public License for more details.
*
* You should have received a copy of the GNU Affero General Public License
* along with this program. If not, see <https://www.gnu.org/licenses/>.
*/
// export default {
module.exports = {
'_trapcss': trapcss,
}
This file also includes the APGL license that was selected when the package was bootstrapped. It uses the /*! notation to preserve the comment. If you chose MIT license, you'll also have a similar, but shorter notice. For other licenses, you'd have to add a comment manually. Also, for AGPL, we don't include the copyright on top of each file as I believe it's redundant, but feel free to do it your way.
The entry to Depack imports our API, and assigns it to the modules.export object. This will allow to access those methods (currently, just 1) from the compile dir. However, because we ran the ÀLaMode transpiler on the src folder, the module.exports = got renamed into export default, therefore just manually change it back now.We'll need to create a second file, called template in compile/template.js:
const { _trapcss } = require('./trapcss')
/**
* @methodType {_trapcss.trapcss}
*/
function trapcss(config) {
return _trapcss(config)
}
module.exports = trapcss
/* typal types/index.xml namespace */
The template file is not meant for execution, but provides a blueprint for generation of our main file (called main because of the main field in package.json). It has the @methodType {_trapcss.trapcss} annotation, that declares the type of the function, so that its JSDoc can be expanded. It also contains the typal marker at the bottom, so that we can embed our Config and Return types into the main file as well. To generate the real JavaScript file, we'll need to run the yarn npm run d command, that will run template and d1 scripts in series. The template command is the following: typal compile/template.js -T compile/index.js -t types/api.xml:
- compile/template.js, is the path to the template file.
- -T compile/index.js, the path to the main file to be generated.
- -t types/api.xml, is the path to types that should be used. It could also point to the dir itself, however because we also included arguments.xml for our binary, that doesn't allow us to simply pass types.
The d1 command expands the typal marker in the index.js produced from the template — typal compile/index.js types/index.js -u -t types/index.xml:
- compile/index.js types/index.js, paths to files with typal markers that needs embedding typedefs.
- -u, tells Typal to use namespaces rather than simple type names.
- -t types/index.xml, the location of types, can be skipped.
After the two commands are run, we'll have a production-ready entry file. Let's have a look at what is being produced as the main:
const { _trapcss } = require('./trapcss')
/**
* Parses the supplied HTML and CSS and removes
unused selectors. Also removes empty CSS rules.
* @param {_trapcss.Config} config Options for the program.
* @param {string} config.html The input HTML.
* @param {string} config.css The CSS to drop selectors from.
* @param {boolean} [config.keepAlternate=false] Whether to keep the `@alternate` comment for
* Closure Stylesheets. Default `false`.
* @param {(sel: string) => boolean} [config.shouldDrop] Whether _TrapCSS_ should remove this selector.
* The `shouldDrop` hook is called for every CSS selector
* that could not be matched in the html. Return `false`
* to retain the selector or `true` to drop it.
* @return {_trapcss.Return}
*/
function trapcss(config) {
return _trapcss(config)
}
module.exports = trapcss
/* typal types/index.xml namespace */
/**
* @typedef {_trapcss.Config} Config `@record` Options for the program.
* @typedef {Object} _trapcss.Config `@record` Options for the program.
* @prop {string} html The input HTML.
* @prop {string} css The CSS to drop selectors from.
* @prop {boolean} [keepAlternate=false] Whether to keep the `@alternate` comment for
* Closure Stylesheets. Default `false`.
* @prop {(sel: string) => boolean} [shouldDrop] Whether _TrapCSS_ should remove this selector.
* The `shouldDrop` hook is called for every CSS selector
* that could not be matched in the html. Return `false`
* to retain the selector or `true` to drop it.
* @typedef {_trapcss.Return} Return `@record` Return Type.
* @typedef {Object} _trapcss.Return `@record` Return Type.
* @prop {string} css The dropped CSS.
* @prop {!Set<string>} sels The used selectors.
*/
The entry file to our package contains an annotated function that wraps a method from the API. Since we decorated it with JSDoc, we'll be able to receive autocompletion hints on the config type when consuming the library from other packages. Our config is declared as a type at the bottom, but the config property of the function is also expanded into individual @params. This is to increase the visibility of the parameters, which will now appear on the function's description:
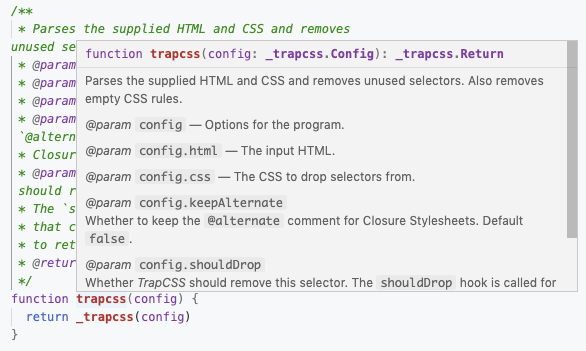
This allows people to read the full description of the argument, without having to go through each individual property when expanding the config. Without this feature, the description doesn't give the full picture:
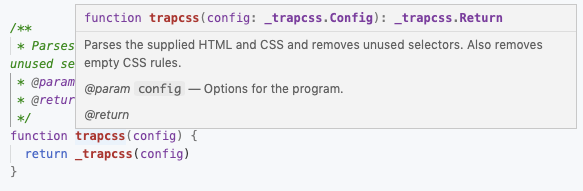
All typedefs should be embedded into the main file, which acts as a repository for types. This will make sure that types are always available. Do you remember how we imported the config type from types/index.js in the previous part?
/**
* @typedef {import('..').Config} _trapcss.Config
* @typedef {import('..').Return} _trapcss.Return
*/This is because the main file is treated as the go-to place for types. Using templates allows to treat source code independent from the API specification, and plug in the implementation into JSDoc-annotated shells for code. It's kind of similar to TypeScript that provides .d.ts types, however in pure JavaScript. If you're exporting a class, you can also use the @constructor tag in the template, to generate a class shell.
const { _Cl } = require('./depack')
/** @constructor {_ns.MyClass} */
class MyClass extends _Cl {}The body of the class will then be generated, however there's no annotations for properties, only member methods. For example, @goa/router uses this method. Another way to template classes, is to include a typedef of a class in a file, and then use typeof operator when proxying the type:
const { _Goa, _Context } = require('./koa')
/**
* An application constructor.
* @type {new (options?: ApplicationOptions) => Application)}
*/
const $Goa = _Goa
/**
* The default context constructor.
* @type {new () => Context}
*/
const $Context = _Context
module.exports = $Goa
module.exports.Context = $ContextThis also works pretty well, however you won't be able to access JSDoc for static methods.
In short, we need to use templates to enrich our compiled code with JSDoc annotations, by providing simple shells that are documented with JSDoc comments. All typedefs are also included in the main JS file to be accessed by methods. They are also imported from the source code, either directly or via such files as types/index.js that hold methods' typedefs for development purposes, as the main file is the source of truth for types.
Running Compiler
The next step is to execute the compiler. The package that we installed contained a jar file, which needs to be passed to Java along with arguments. The arguments must also contain the list of all JS files in the program. That's why Depack also contains a regex-based static analysis tool that scans all files for import statements, and builds a full list of all files. The algorithm can also detect require calls, however if at some point you want to use dynamic linking (so that a dependency is required at runtime, rather than compiled into your program), you can use the following construct:
const pckg = require(/* depack */ 'dynamic-linking')In this case, the regex won't pick up the require call. In addition, no require calls from the entry file that we're compiling end up in the arguments. Initially, this was a bug, but I decided to keep it as is, so that in binaries, we can simply do something like that:
if (_version) {
console.log('v%s', require('../../package.json')['version'])
}Importing JSON files with import also doesn't work in Closure (at least at the time of writing), so you'll need to require them, or read as text and use JSON.parse method to extract JS objects from them.
Since we've prepared and tested our source code already, we can just execute the compiler with yarn npm run lib command — depack src/depack.js -o compile/trapcss.js -a -c -p --source_map_include_content:- src/depack.js, the entry point to compile.
- -o compile/trapcss.js, the output location.
- -a, enable advanced optimisation.
- -c, indicates to Depack that we're compiling a Node.JS package which enables Node externs.
- --source_map_include_content, to include content in source maps. The content is pretty useful, however VSCode won't be able to print the values of variables when you hover over then during debugging in which case you might want to pass "sourceMaps": false in your launch config when debugging compiled libs.
Other options could include -p, for pretty output, or -O ES5, to compile into really old code that could probably be able to run on Node 4 (given the API is supported). The default language output is ES2018. Source maps could be disabled with -S. Any other options to the compiler can also be just passed after the main command. And that's it, there's no config or anything.
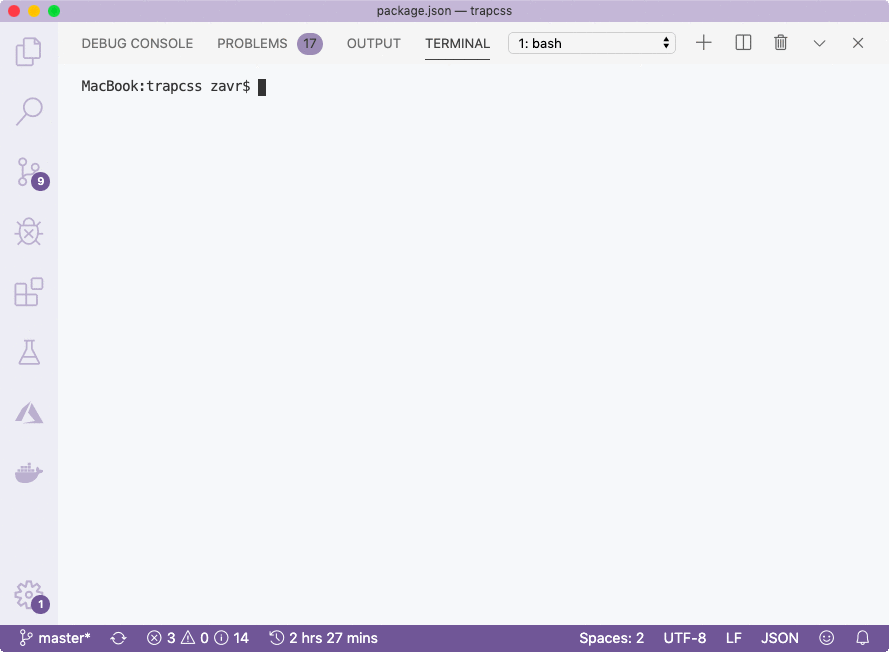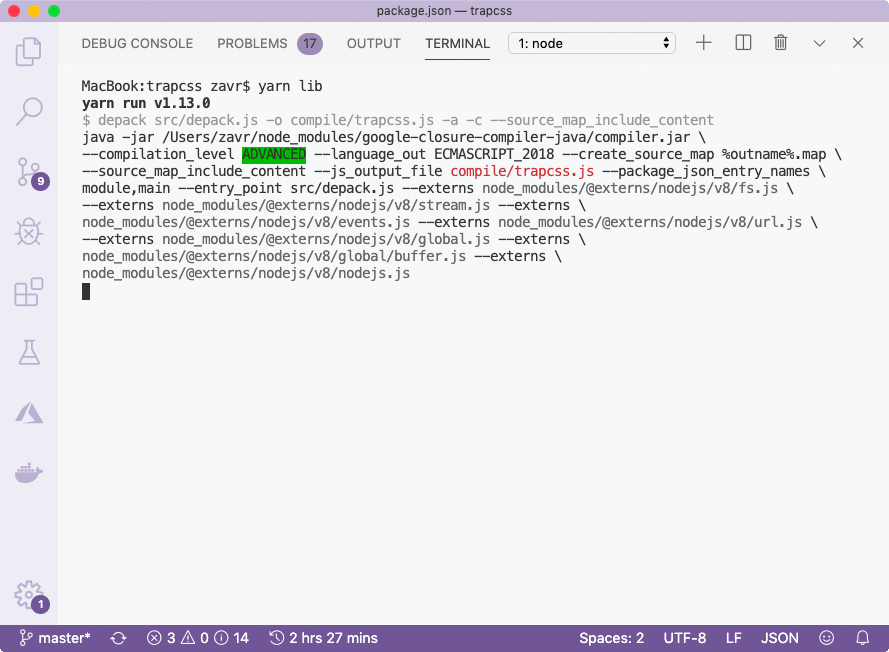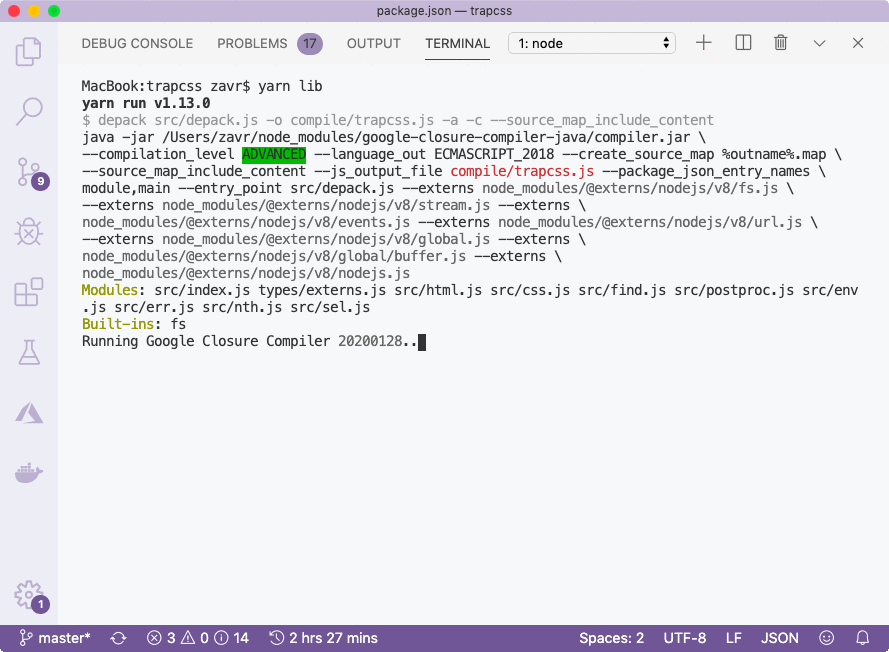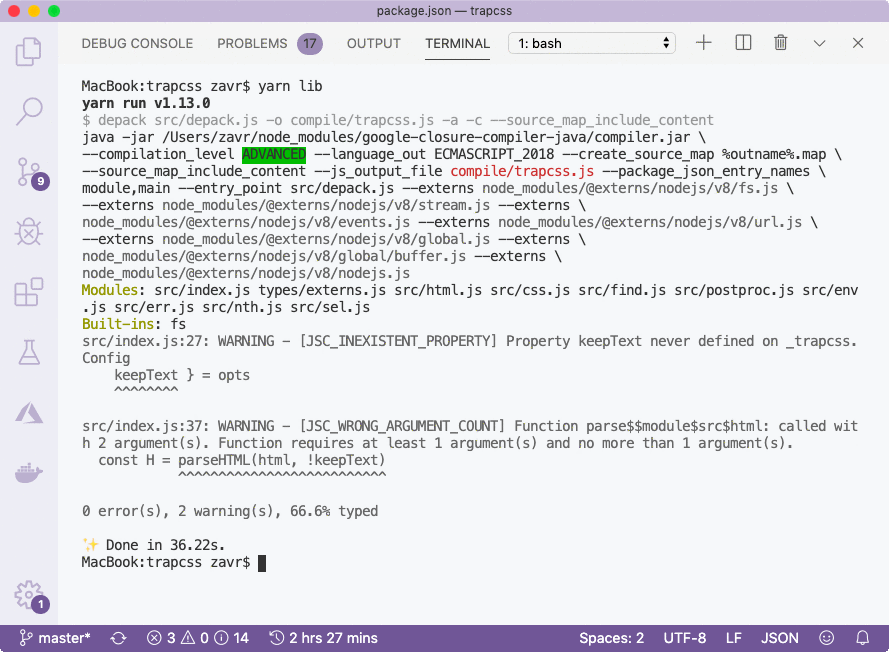
Because of type checking, we also received a number of warnings. In part I, we kept the keepText argument, even though it wasn't used in the source code. The compiler was able to pick up the fact that the config type does not include such property, and that the parseHTML method doesn't accept the second argument either. It's really great to use compiler to polish our code so that there are no inaccuracies like that left and our source is 100% professional. It is not possible with Babel, perhaps only with TypeScript.
When we come to remove the keepText to fix the warning, let's also add the original MIT copyright on the package. The copyright owner didn't include any comment that would have to be preserved, therefore we're under no obligation to include it in our code (only in documentation), but let's do it anyway as good practice. I use the following template for MIT:/*!
* dropcss by Leon Sorokin
* https://github.com/leeoniya/dropcss
* Copyright(c) 2020
* MIT Licensed
*/The compiled code is saved into compile/trapcss.js file. Let's just have a quick look.
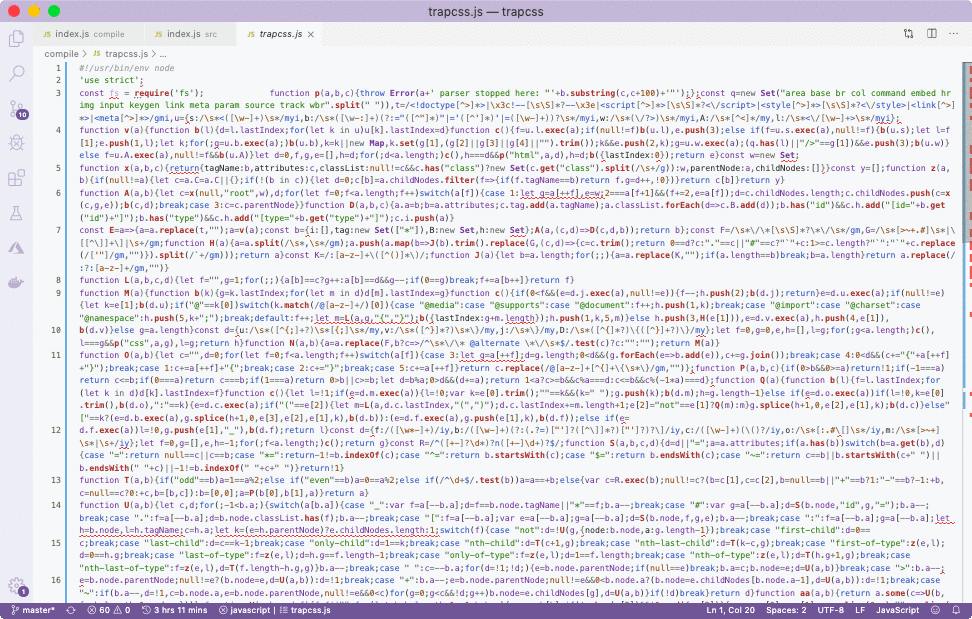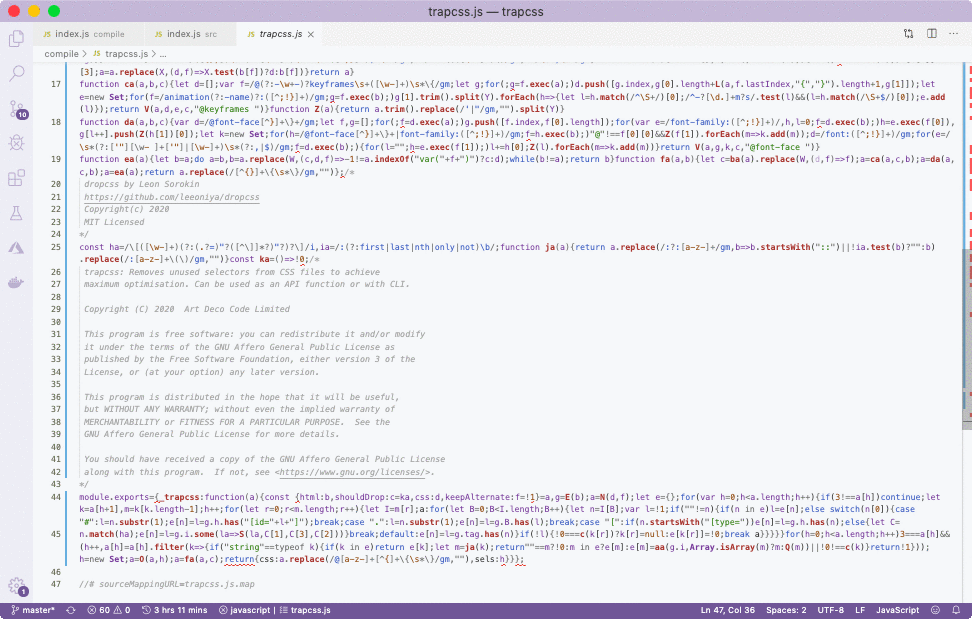
There's the use strict directive, both licenses and the assignment to the module.exports property. On top, there's also a shebang which is not relevant to compiled libraries, but is needed when we'll be compiling binaries, however Depack just keeps it anyway since it doesn't have any negative effect. If you need to disable use strict, you can pass the -s flag to Depack.
The template has already been prepared so now we actually have our package ready to be published, but we'd like to test the compiled module prior to publishing. Since we should be careful with advanced optimisation that can rename property names, we can now run all our tests but override the import of the source code to import of the compiled code. This is achieved with yarn npm run test-compile command — yarn test -e test-compilenpm test -- -- -e test-compile. It simply calls the test script, but passes the test-compile variable as testing environment. The environments are configured in the .alamoderc file:
{
"env": {
"test-compile": {
"import": {
"replacement": {
"from": "^((../)+)src$",
"to": "$1compile"
}
}
}
}
}Now every time we require ../../src from test, the transpiler will update it to ../../compile on the fly (the $ is needed in cases when we import methods from other files in the lib for unit testing, which would break testing as paths like compile/html.js don't exist). We can also set it to just ../.. since it will resolve to our package.json and read the main field from there. To ensure that the remapping actually happens, we can add a simple throw new Error(1) in the compile/index.js file and try to run this command.
Testing compile bin
Error: 1
Could not require test/spec
at Object.<anonymous> (/Users/zavr/adc/trapcss/compile/index.js:2:7)
at Module.p._compile (/Users/zavr/adc/trapcss/node_modules/alamode/compile/depack.js:49:18)
at Object.h.(anonymous function).y._extensions.(anonymous function) [as .js] (/Users/zavr/adc/trapcss/node_modules/alamode/compile/depack.js:51:7)
error Command failed with exit code 1.There was an error, so the imports renaming was correct. Let's remove the error and run test again.
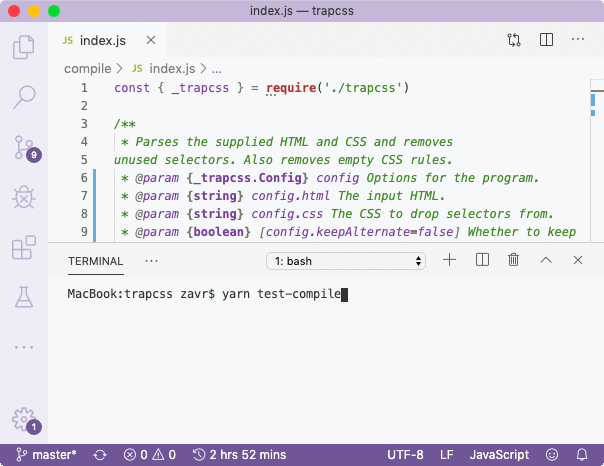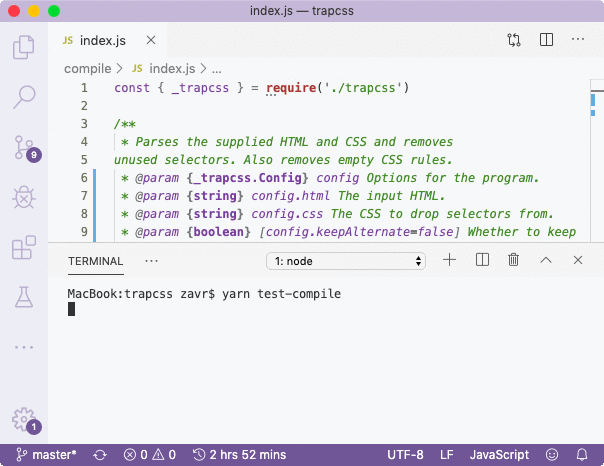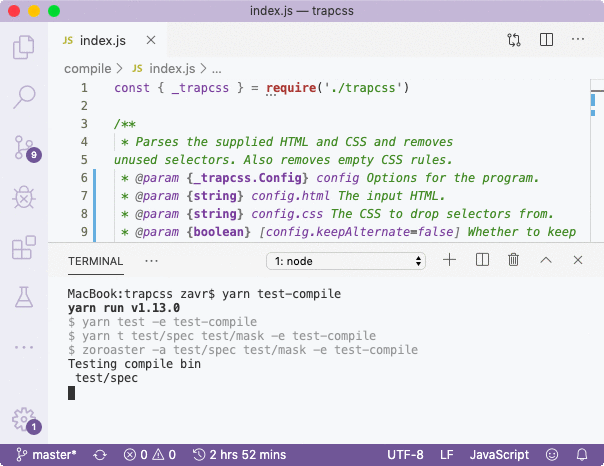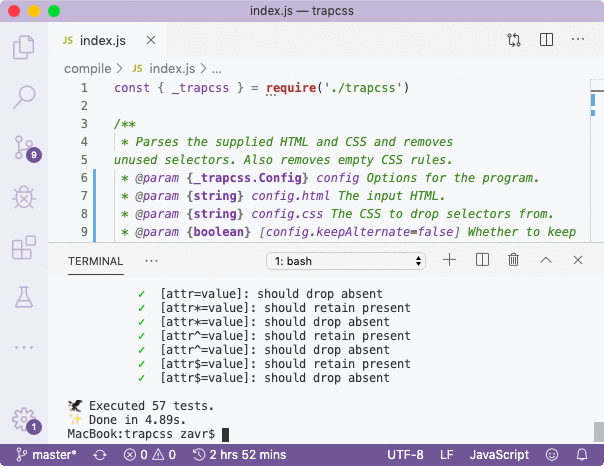
All tests pass which is good news! We can also create a test file called t.js in the project dir, and import the library to test for the presence of autocompletions:
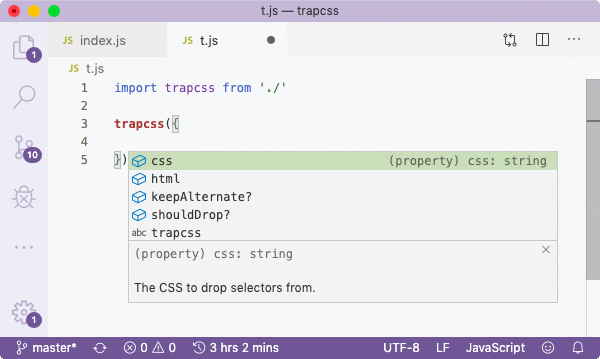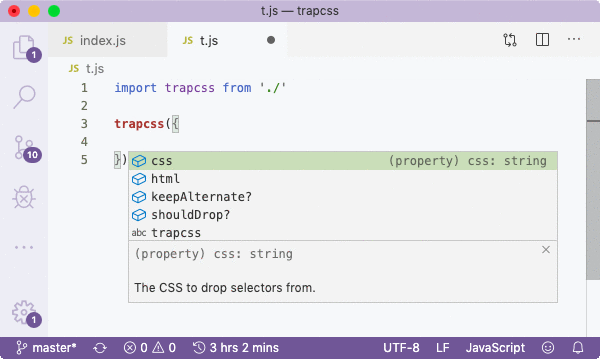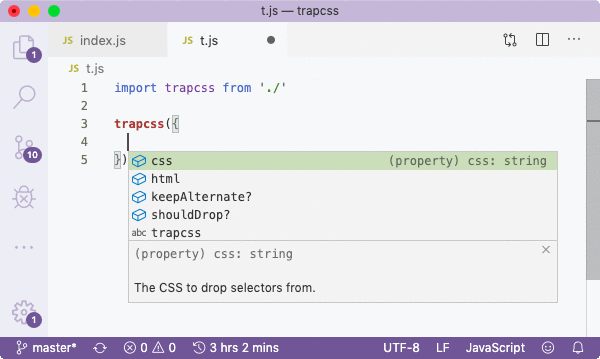
After manual testing, we find that everything is correct. In NodeTools 2, we'll include a tool to write autocompletion tests since it's not feasible to keep rerunning such tests by hand. But for now, you can use this strategy.

Binary Executable
Many packages come with a binary — a Node script that can be run from the CLI. There are many usages of such scripts, including on CI, or to perform any routine operation from the command line. Binaries need to be defined in package.json:
"bin": {
"trapcss": "compile/bin/trapcss.js",
"trapcss-dev": "src/bin/index.js"
}The main bin is pointing to the compiled version, whereas we also add the dev version, for when we link the package using yarn npm link. This will make its source code executable system-wide without having to recompile it every time for changes. The index.js file is the entry point to the development version:
#!/usr/bin/env node
require('alamode')()
require('./trapcss')It simply instantiates the ÀLaMode hook that will transpile modules on the file. It is not used when the binary is built/compiled. We also have a dev script "dev": "node src/bin" so that we can run yarn npm run dev from the project folder when testing.
CLI Arguments
The key requirement for such scripts is to read arguments from the process.argv array, to parse input flags and options to the program. There are packages that allow to do that, but in NodeTools, we take a different approach. We'll keep our arguments definitions in the types/arguments.xml file:
<arguments>
<arg command multiple name="input">
The HTML files to read.
</arg>
<arg name="css" short="c">
The CSS file to drop selectors from.
</arg>
<arg name="output" short="o">
The destination where to save output.
If not passed, prints to stdout.
</arg>
<arg boolean name="help" short="h">
Print the help information and exit.
</arg>
<arg boolean name="version" short="v">
Show the version's number and exit.
</arg>
</arguments>Using XML schema, we can maintain the argument specification, and then create a special file called get-args.js, using the argufy package. The script is defined as the args job in package.json — argufy -o src/bin/get-args.js. The default location of arguments is types/arguments.xml, so we don't need to specify any input. The output, on the other hand, is to be written to src/bin/get-args.js. From the specification that we drew, this is the output that is produced:
import argufy from 'argufy'
export const argsConfig = {
'input': {
description: 'The HTML files to read.',
command: true,
multiple: true,
},
'css': {
description: 'The CSS file to drop selectors from.',
short: 'c',
},
'output': {
description: 'The destination where to save output.\nIf not passed, prints to stdout.',
short: 'o',
},
'help': {
description: 'Print the help information and exit.',
boolean: true,
short: 'h',
},
'version': {
description: 'Show the version\'s number and exit.',
boolean: true,
short: 'v',
},
}
const args = argufy(argsConfig)
/**
* The HTML files to read.
*/
export const _input = /** @type {!Array<string>} */ (args['input'])
/**
* The CSS file to drop selectors from.
*/
export const _css = /** @type {string} */ (args['css'])
/**
* The destination where to save output.
If not passed, prints to stdout.
*/
export const _output = /** @type {string} */ (args['output'])
/**
* Print the help information and exit.
*/
export const _help = /** @type {boolean} */ (args['help'])
/**
* Show the version's number and exit.
*/
export const _version = /** @type {boolean} */ (args['version'])
/**
* The additional arguments passed to the program.
*/
export const _argv = /** @type {!Array<string>} */ (args._argv)The program generated the config, that will be passed to argufy at runtime, to create the args object. Then, each of arguments is actually casted into its correct type, annotated with description and declared as a named export. This will allow to statically import those arguments from the binary. Such approach enables type checking using Closure Compiler, as arguments are constructed statically. argufy doesn't have any dependencies, but if we compile the binary, it will also be merged into it meaning there's absolutely no overhead into using it. Because input is specified as multiple command, it will be an array of strings, so that we can pass multiple paths to HTML files.
- Read more about argufy;
- Multiple arguments.xml files can be kept, for different semantic functionality;
- Short aliases can be reused between commands, check out logarithm;
- At the moment, an argument cannot be both flag (boolean) and standard argument, e.g., trapcss -c AND trapcss -c path.css are not possible at the same time. I'll be adding this later on.
Implementation
The template has already come with some binary source code, for example for printing version number and usage information. The usage string is constructed with the usually package, that accepts a description, example, line and usage itself. The usage is made using the reduceUsage method from argufy, based on the arguments config that was also exported from the get-args.js file. It will create a 2-column table with full and short arguments' names and their descriptions.
import usually from 'usually'
import { reduceUsage } from 'argufy'
import { readFileSync, writeFileSync } from 'fs'
import { c } from 'erte'
import { _input, _output, argsConfig, _css, _version, _help } from './get-args'
import trapcss from '../'
/*!
* TrapCSS: Remove unused CSS selectors based on HTML files.
*
* Copyright (C) 2020 Art Deco Code Limited
*
* This program is free software: you can redistribute it and/or modify
* it under the terms of the GNU Affero General Public License as
* published by the Free Software Foundation, either version 3 of the
* License, or (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU Affero General Public License for more details.
*
* You should have received a copy of the GNU Affero General Public License
* along with this program. If not, see <https://www.gnu.org/licenses/>.
*/
if (_help) {
const usage = usually({
description: 'Remove unused CSS',
example: 'trapcss index.html example.html -c style.css -o style-dropped.css',
line: 'trapcss input.html[,n.html,...] -c style.css [-o output] [-hv]',
usage: reduceUsage(argsConfig),
})
console.log(usage)
process.exit(0)
} else if (_version) {
console.log(require('../../package.json').version)
process.exit(0)
}
if (!_css) {
console.error('Please pass CSS path')
process.exit(1)
}
const css = /** @type {string} */ (readFileSync(_css, 'utf8'))
// whitelist
let whitelist = new Set()
_input.forEach((input) => {
const html = /** @type {string} */ (readFileSync(input, 'utf8'))
const { sels } = trapcss({
css,
html,
})
sels.forEach(sel => whitelist.add(sel))
})
const cleaned = trapcss({
html: '',
css,
shouldDrop: sel => !whitelist.has(sel),
})
if (_output) {
writeFileSync(_output, cleaned.css)
console.error('Output written to %s', c(_output, 'yellow'))
} else {
console.log(cleaned.css)
}We can see what the usage looks like by calling the dev script: yarn npm run dev -- -h:
Remove unused CSS
trapcss input.html[,n.html,...] -c style.css [-o output] [-hv]
input The HTML files to read.
--css, -c The CSS file to drop selectors from.
--output, -o The destination where to save output.
If not passed, prints to stdout.
--help, -h Print the help information and exit.
--version, -v Show the version's number and exit.
Example:
trapcss index.html example.html -c style.css -o style-dropped.cssThis presentation might be different from how you want it to look like, so feel free to implement your own usage function from the args config, or submit a PR to the usually package with new options for styling.
Moreover, we required package.json at runtime, which means that it won't be built into the compiled code, and will remain as require call. Requires from the entry file don't make it to the dependency list during static analysis, but if we wanted to make dynamic import anywhere else, it'd have to be broken up:const pckg = require(/* dpck */ 'dynamic-import')version is a recognised option by the compiler, so we don't have to use quoted props, for other fields, we'd have to refer to them like require('../../package')['main'] to avoid renaming.
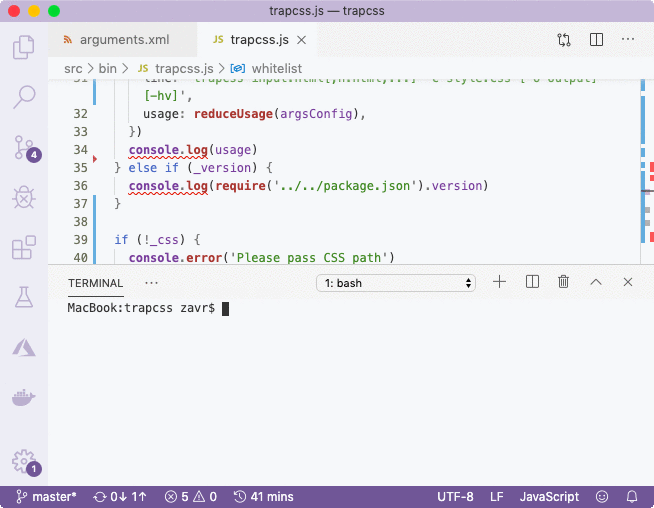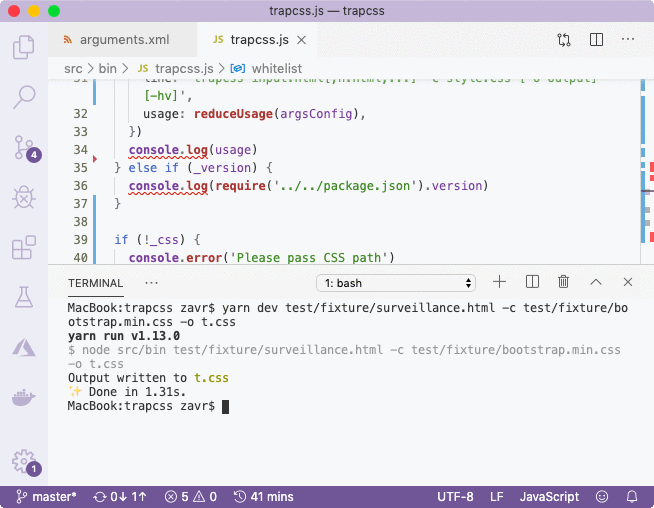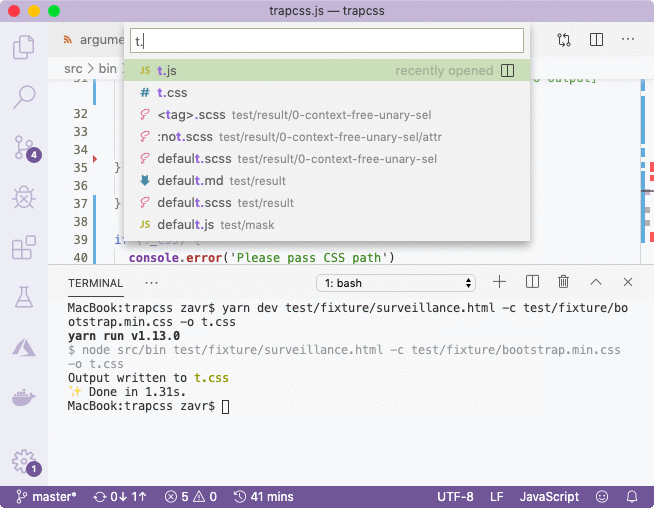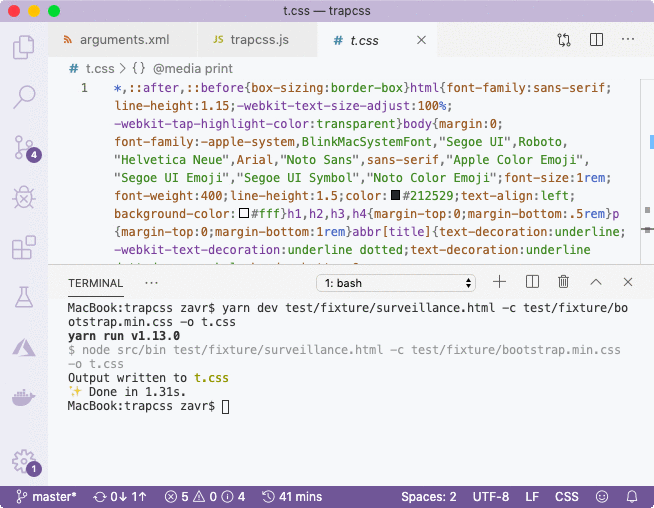
Next, we check if the CSS was supplied via the arguments. If it wasn't we print an error message and exit with status code 1, which means that the program wasn't executed successfully and is a unix convention. Otherwise, we'll read the CSS file, using standard readFileSync. Typically, in Node, we're trained to use promises for non-blocking IO, however because we're not running a server, and simply executing a script, it's absolutely appropriate to use sync operations in this case (unless we're reading/writing many files in parallel). We used casting, because if the second argument (encoding) is not passed to readFileSync, it will return a buffer, but the compiler does not support overloading, so we have to explicitly cast the return type. This is done by wrapping the value in brackets:/** @type {string} */ (readFileSync(input, 'utf8'))DropCSS provides a strategy for reading multiple input files. We create a whitelist set, and then for each HTML file, execute the trapcss method against it and CSS, and add selectors to the set. In the end, we simply pass an empty string as HTML, but use shouldDrop: sel => !whitelist.has(sel) property of the config that will utilise the accumulated whitelist.
Finally, if the -o argument was passed, we can save the result to a file. If not, we print the output to stdout to the user. We used the c method from erte to print the output location in yellow. It also contains the b method to color the background of strings, and the two can be combined. The template came with indicatrix package also that would print a loading indicator (triple ellipse) however we didn't have any async operations so it could be removed.
Fork Testing
We already used some mask testing in , but one of the best applications of masks is to test forks. A fork is a separate Node process spawned from a script itself. They are completely independent processes with separate PIDs, but the fork will by default exit with its parent. Since our binary is a Node program, to test it properly, we need to spawn it via the child_process module. Zoroaster provides an abstraction over fork testing, if you pass fork property to the mask constructor.
import TempContext from 'temp-context'
import Context from '../context'
import makeTestSuite from '@zoroaster/mask'
export default makeTestSuite('test/result/bin/default', {
context: TempContext,
fork: {
/**
* @param {string[]} args
* @param {TempContext} t
*/
async getArgs(_, { write }) {
const html = await write('index.html', this.input)
const [, css] = /<style>([\s\S]+?)<\/style>/.exec(this.css)
const style = await write('style.css', css)
return [html, '-c', style]
},
module: Context.BIN,
preprocess: {
stdout: Context.wrap,
},
},
})By default, the input from mask result is split by whitespace to provide arguments to fork, but we can provide the getArgs method to expand, or override the arguments list. We'll use a testing context called TempContext to write the input of the mask into a temp file ( yarn npm iadd temp-context). For each test, a blank test/temp dir will be created, and removed at the end. The write method returns the path to the new file, so that we can pass it to the program. We then extract the CSS from within the style tag in the mask result (need to wrap it in the style tag for syntax highlighting), and also write it to the temp dir. The new arguments, therefore are: [path-to.html -c path-to.css].
As a preprocessor for output, we also want to wrap the stdout in style tag also, for syntax highlighting. The tag itself has no meaning to tests themselves, it only allows US as developers to work comfortably with mask results. NodeTools is all about usability, and we can even do some cools stuff as folding individual specs in the result file, since they are under ## heading of a markdown file.
Additionally, we had to get the path to the fork from the context's static BIN property, that accounts for the testing environment:
// test/context/index.js
let BIN = 'src/BIN'
if (process.env.ALAMODE_ENV == 'test-compile') {
console.log('Testing compile bin...')
BIN = 'compile/bin/trapcss'
}This will be useful later after we've compiled the binary with Closure.
## keeps span
<html>
<body>
<span>test</span>
</body>
</html>
/* css */
<style>
span {
color: green;
}
</style>
/**/
/* stdout */
<style>
span{color: green;}
</style>
/**/
## removes div
<html>
<body>
<span>test</span>
</body>
</html>
/* css */
<style>
span {
color: yellow;
}
div {
color: green;
}
</style>
/**/
/* stdout */
<style>
span{color: yellow;}
</style>
/**/We only do a couple of tests to make sure that the binary doesn't throw any errors and processes arguments correctly. Most of the unit tests were done on the API, therefore it'd be redundant to test the same functionality twice. However, we could potentially construct a mask that would use input from mask results to the API to adapt them to pass to the CLI, but I won't do it here. Since mask results are just text files, they can be reused according to your imagination.
import TempContext from 'temp-context'
import Context from '../context'
import makeTestSuite from '@zoroaster/mask'
export const output = makeTestSuite('test/result/bin/output', {
context: TempContext,
fork: {
/**
* @param {string[]} args
* @param {TempContext} t
*/
async getArgs(args, { resolve }) {
return [...args, '-o', resolve('style-trap.css')]
},
module: Context.BIN,
},
/**
* @param {TempContext} t
*/
async getResults({ read }) {
const s = await read('style-trap.css')
return Context.wrap(s)
},
})
The second test is almost the same as the first one, except that we add the output argument to the list of arguments from the input, instead of completely overriding the arguments array. The path to the output is generated with the resolve method from the temp context, which we passed in the context property. The question is then how to test the output of the program? To do that, we need to implement the getResults method that will also receive the context, so that we can call the read method from testing API. As previously, we want to wrap the output for syntax highlighting.
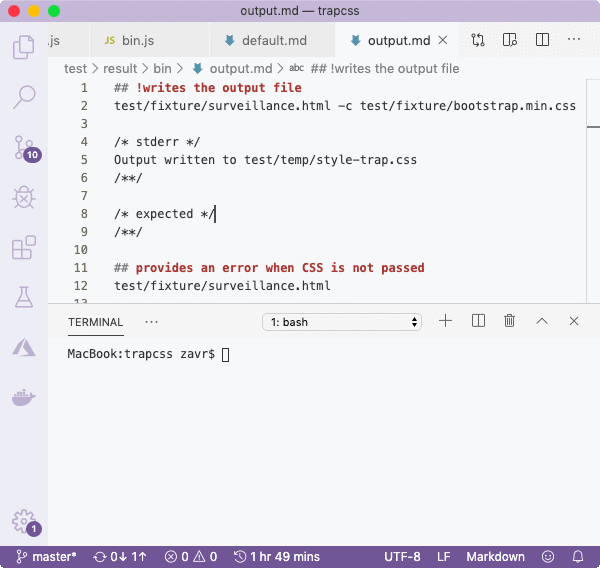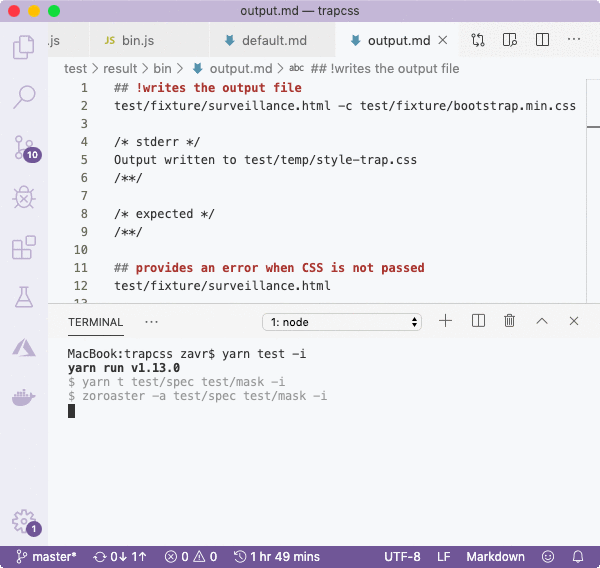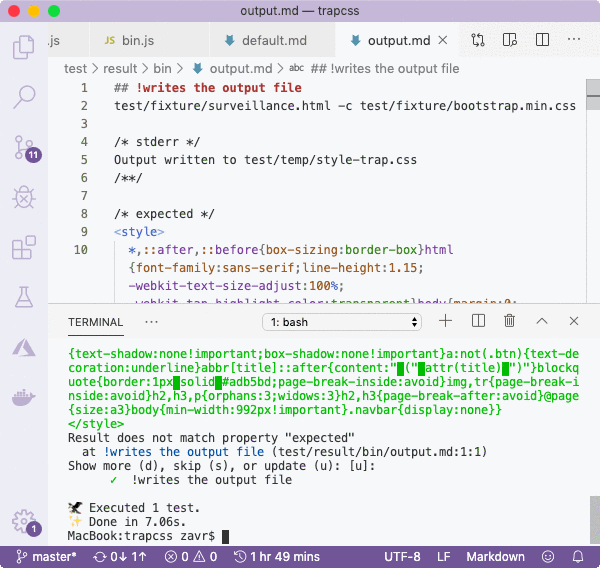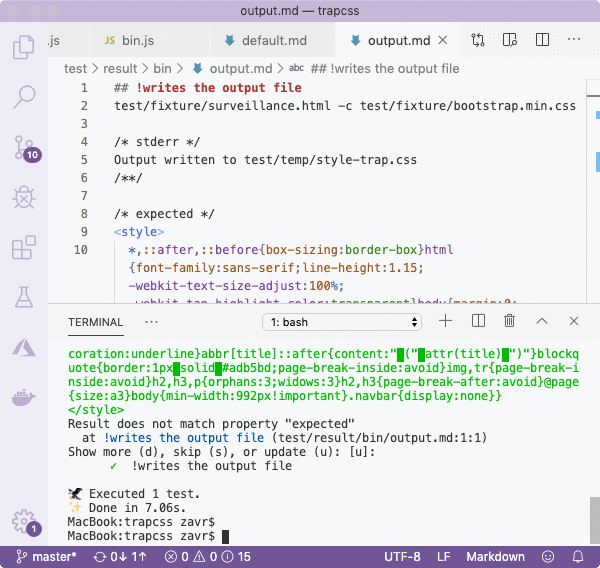
## writes the output file
test/fixture/surveillance.html -c test/fixture/bootstrap.min.css
/* stderr */
Output written to test/temp/style-trap.css
/**/
/* expected */
<style>
*,::after,::before{box-sizing:border-box}html{...}
</style>
/**/
The mask result provides 2 properties: stderr and expected. We're not testing for stdout since there's no output on this stream, and we implemented the getResults method to read the expected result from a file in the temp folder.
As previously, we could leave the mask result values blank, and run tests in interactive mode yarn npm test -- -i, for the testing framework to populate them for us.
For the final test, we'll make the simplest mask possible, by only passing the path to the binary:
export const stress = makeTestSuite('test/result/bin/stress', {
fork: Context.BIN,
})When there's no additional configuration, only stdout, stderr and code properties are asserted on.
## cleans the css
test/fixture/surveillance.html -c test/fixture/bootstrap.min.css
/* stdout */
*,::after,::before{box-sizing:border-box}html{...}
/**/
## gives error when CSS is not passed
test/fixture/surveillance.html
/* stderr */
Please pass CSS path
/**/
/* code */
1
/**/In the first test, like before, we passed paths to HTML and CSS, but we didn't need to use the temp context since the output is printed to stdout. In the second test we added the code property to test that the fork will exit with code 1 when a path to the CSS file is not passed, and that stderr contains the error message.
As you can see, testing forks is very simple with Zoroaster that provides means to setup tests to run parallel processes, and assert on outputs. The tests themselves are not run in parallel, but there's no point to it anyway, as running them in parallel will slow down the CPU and consume more memory, so that there's no difference between running 5 tests in parallel that take 1 second each, or 5 tests in series that take 0.2 seconds each, so don't listen to anyone who advertises parallel testing as an advantage, unless it's IO time that is being parallelised, and not CPU time.Even if a program required interaction from stdin, such as entering answers, we could still test it by either providing the [stderr]Inputs property of the mask, or via the inputs property in the mask result.
Fork testing is more expensive as it requires time to spawn forks, therefore it's preferable to do as many unit tests as possible, and design binary in such a way as it would be possible to require commands called from binary in tests, instead of spawning forks. That's why the template comes with the init command, but it could be removed now since our binary is fairly straight-forward.Bin Compile
We now want to compile the binary. NodeTools is perfect for this task, as the program produced will have no dependencies at all. The package.json file already comes with a command to run Depack on the binary yarn npm run compile (the lib script is to compile library instead, which we've already done). The script evaluates to depack src/bin/trapcss -o compile/bin/trapcss.js -a -c -S --externs types/externs.js:
- src/bin/trapcss, the file to compile, from which all dependencies will be statically analyzed.
- -o compile/bin/trapcss.js, the path to the output file.
- -a, advanced compilation.
- -c, compilation flag (needed to enable Node externs).
- -S, no source maps, as we're not expecting that our bin will be debugged, unlike library, which might be jumped in.
- --externs types/externs.js, in the library, we imported externs from src/depack.js file, however we can also pass it via the argument to CLI. Previously, src/depack.js that imported externs wasn't ever run and only passed to Closure as entry, but if we used an import in bin, the externs file would be evaluated which is unnecessary.
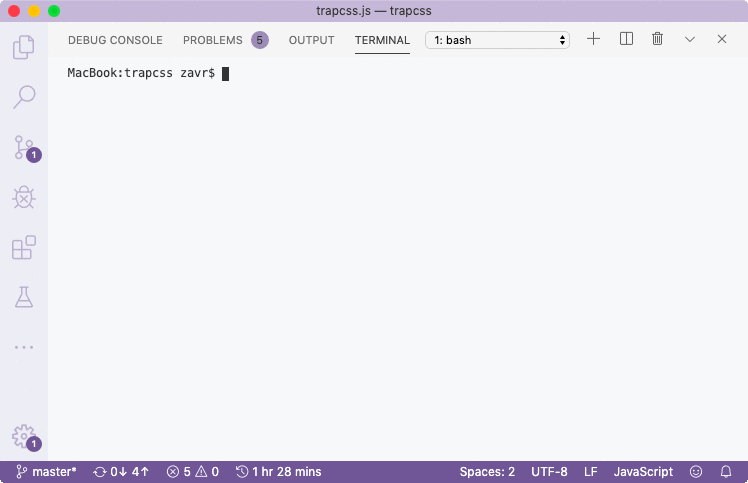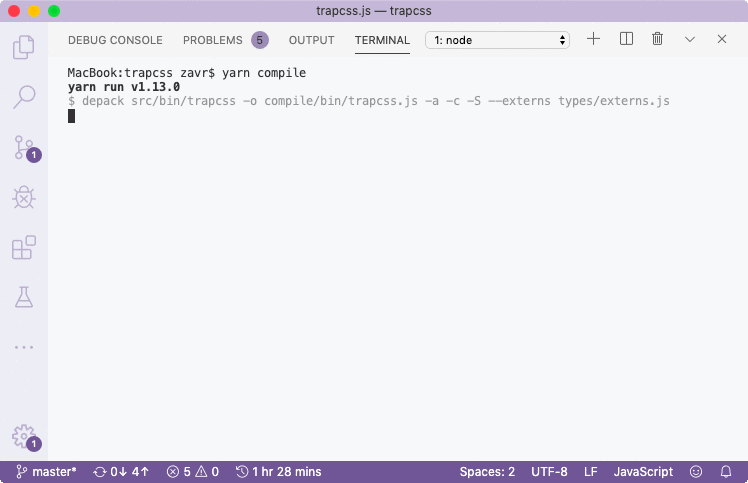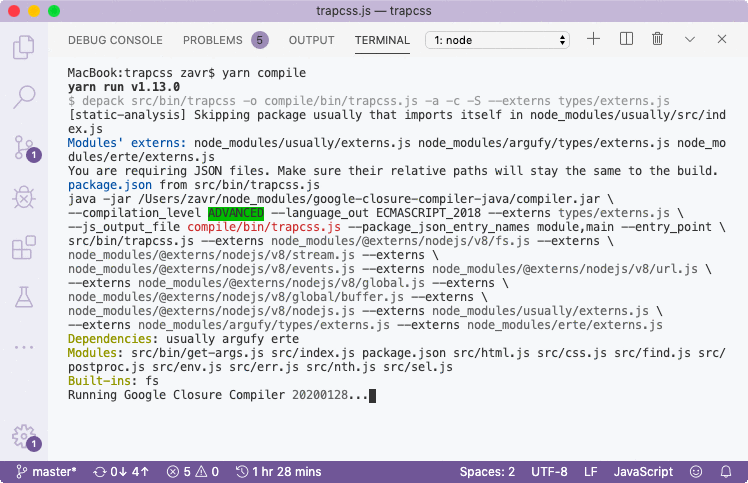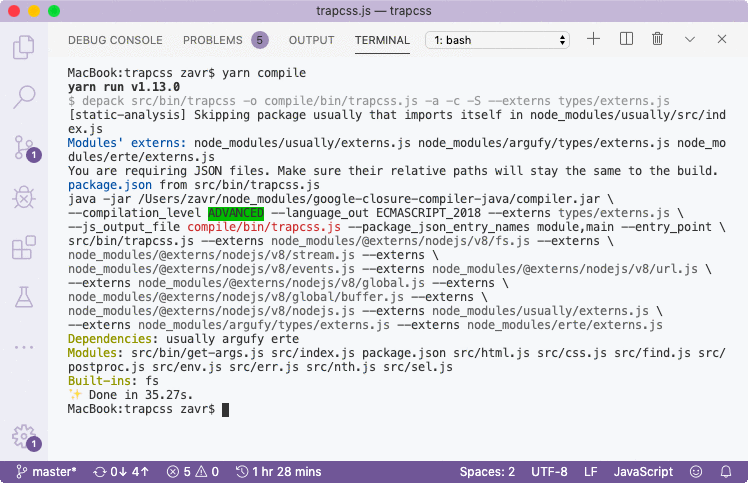
Depack will discover all built-in Node modules, add apply externs for those. Global and Buffer externs are always added (even if Buffer isn't used). You might see a message "Skipping package usually that imports itself in node_modules/usually/src/index.js", because usually has an example usage where in its JSDoc it gives a snippet with an import:
/**
* Generate a usage string.
* @param {!_usually.Config} config The configuration object.
* @example
```
import usually from 'usually'
const res = usually({
description: 'A test command-line application',
})
```
*/
export default function usually(config = { usage: {} }) {Static analysis is based on regexes, so if you ever encounter any problems with it, e.g., false positive imports detection where your imports are just placed in a string, for example, you should break up the import so it becomes undetectable:
// false positive
const myString = `// auto-generated code
import package from 'package'
`
// becomes
const myString = `// auto-generated code
i` + `mport package from 'package'
`I know it's not perfect, but I'd rather keep simple regexes for the analysis of ECMA modules, instead of increasing complexity by building of ASTs etc. The whole purpose of NodeTools is to be really simple yet effective.
The result of compilation is saved into the compile/bin/trapcss.js, and the file is assigned executable rights so that it can be called from shell, as it has got the shebang with the node env.#!/usr/bin/env node
'use strict';
const fs = require('fs'); function q(){var a={description:"Remove unused CSS",example:"trapcss index.html example.html -c style.css -o style-dropped.css",line:"trapcss input.html[,n.html,...] -c style.css [-o output] [-hv]",usage:v()};const {usage:b={},description:c,line:d,example:f}=a;a=Object.keys(b);const g=Object.values(b),[e]=a.reduce(([h=0,m=0],p)=>{const t=b[p].split("\n").reduce((r,n)=>n.length>r?n.length:r,0);t>m&&(m=t);p.length>h&&(h=p.length);return[h,m]},[]),k=(h,m)=>{m=" ".repeat(m-h.length);return`${h}${m}`};
a=a.reduce((h,m,p)=>{p=g[p].split("\n");m=k(m,e);const [t,...r]=p;m=`${m}\t${t}`;const n=k("",e);p=r.map(u=>`${n}\t${u}`);return[...h,m,...p]},[]).map(h=>`\t${h}`);const l=[c,` ${d||""}`].filter(h=>h?h.trim():h).join("\n\n");a=`${l?`${l}\n`:""}
${a.join("\n")}
`;return f?`${a}
Example:
${f}
`:a};const w=(a,b,c,d=!1,f=!1)=>{const g=c?new RegExp(`^-(${c}|-${b})$`):new RegExp(`^--${b}$`);b=a.findIndex(e=>g.test(e));if(-1==b)return{argv:a};if(d)return{value:!0,index:b,length:1};d=a[b+1];if(!d||"string"==typeof d&&d.startsWith("--"))return{argv:a};f&&(d=parseInt(d,10));return{value:d,index:b,length:2}},x=a=>{const b=[];for(let c=0;c<a.length;c++){const d=a[c];if(d.startsWith("-"))break;b.push(d)}return b},v=()=>{var a=z;return Object.keys(a).reduce((b,c)=>{const d=a[c];if("string"==typeof d)return b[`-${d}`]=
"",b;c=d.command?c:`--${c}`;d.short&&(c=`${c}, -${d.short}`);let f=d.description;d.default&&(f=`${f}\nDefault: ${d.default}.`);b[c]=f;return b},{})};const A=fs.readFileSync,B=fs.writeFileSync;/*
diff package https://github.com/kpdecker/jsdiff
BSD License
Copyright (c) 2009-2015, Kevin Decker <kpdecker@gmail.com>
*/
const aa={black:30,/* ... */}You might see the copyright for the diff package, as there's a script in Erte (string coloring) to diff strings. Although it was dropped by Closure's tree shaking, the comment is left over anyway as Closure preserves all important comments. Depack will implement its own tree shaking, as much as possible, in future versions, to limit the number of JS files passed to the compiler.
To test the package, I callnode compile/bin/trapcss.js test/fixture/surveillance.html \
-c test/fixture/bootstrap.min.cssand check if the output is printed to stdout which it is.
We also have to test the produced binary. Our test-compile script will set the appropriate environment, and since the path to the BIN for mask-testing comes from the context, it will equal to compile/bin/trapcss, so that the compiled module, and not our source code, that will be forked. You'll be able to verify it as Zoroaster will print the confirmation as the first line in the output:Testing compile binAfter tests pass, we know that our compiled bin is fully functional.
CLI Documentation
I want to let my users know how to use TrapCSS from the CLI. Without NodeTools, I'd have to manually execute the binary, and copy-paste the help output into the README file. But we want to automate this process, to
- Save time taken to manually copy-paste data between terminal and documentation;
- Prevent documentation from becoming out-of-date when changes are made;
- Detect any errors if there were problems with the binary;
- Turn documentation into specification as our program will now always confirm to the published contract.
The template already included documentary/2-CLI/index.md file, but we want to build upon it a little bit, by giving a more precise example. We'll need to create example/cli/index.html and example/cli/style.css files with some input data:
<!-- example/cli/index.html -->
<html>
<head>
<title>TrapCSS ftw</title>
</head>
<body>
<p>Hello World!</p>
</body>
</html>/* example/cli/style.css */
html {
background: yellow;
/* @alternate */
background: green;
}
.card {
padding: 8px;
}
p:hover a:first-child {
color: red;
}The updated CLI section of the documentation is pretty simple and includes a 2-column table that lists the examples, and the output. The table with arguments will also be included automatically by the argufy component that comes with Documentary:
## CLI
The package can also be used from the CLI.
<argufy>types/arguments.xml</argufy>
For example, having these two files, we can use `trapcss` from the command line:
<table>
<tr>
<th>HTML file</th>
<th>CSS file</th>
</tr>
<tr>
<td>
%EXAMPLE: example/cli/index.html%
</td>
<td>
%EXAMPLE: example/cli/style.css%
</td>
</tr>
</table>
```console
trapcss:~$ trapcss example/cli/index.html -c example/cli/style.css
```
%FORK-css src/bin/trapcss example/cli/index.html -c example/cli/style.css%
The help can be accessed with the `-h` command:
%FORK src/bin/trapcss -h%
%~%We then give a console line of how to run our binary, and include the %FORK-css% marker, which means that the language of the output block will be CSS for syntax-highlighting on GitHub.
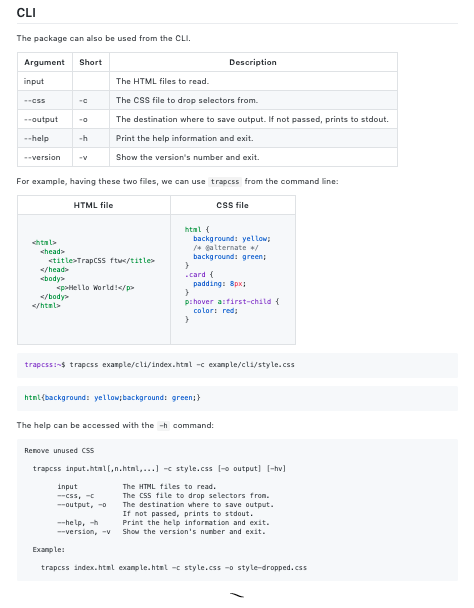
The README section is now compiled in the most automated way possible, leaving us time to work on implementation, testing and new feature design. Remember that we can run yarn npm run doc -- -p "doc cli" to keep Documentary running in watch mode, and automatically push any changes upstream.
Now that we have a 0-dependency binary for TrapCSS, let's add add some more documentation.

Wiki
Putting documentation on GitHub wikis is a great way to organise help to our package. README files can be used to provide initial information about package usage, whereas Wikis can be used to described advanced use cases and intricacies of working with our software. Moreover, unlike website, especially if based on custom domains, Wikis will always remain attached to the package on GitHub. Unfortunately, Wikis have not been that popular, since it wasn't easy to maintain them. Documentary fixes this as it supports automatic compilation of docs into Wikis.
When I was creating a new package from the template, I was asked if I wanted to set up a wiki page, to which I said yes, and had to navigate to GitHub to create the first page. This is because GitHub API doesn't provide a method to automate this, however it's not a problem as it only takes a few clicks. Wikis are represented as separate git trees, so for ease of maintenance, MNP initialised a git submodule called wiki.git in our project, and cloned the tree in there. Now pages from wiki will be compiled into wiki.git and we'll need to push changes to the submodule separately from the main project.The template came with wiki/Developing page, but it can be removed. I'm going to place original documentation from DropCSS into separate pages. The pages could be either directories, or simple MD files. Additionally, special files include _Sidebar.md and _Footer.md, for example our footer uses a component from .documentary/index.jsx:
<footer />We already described how to use the package in README, so let's add the features page.
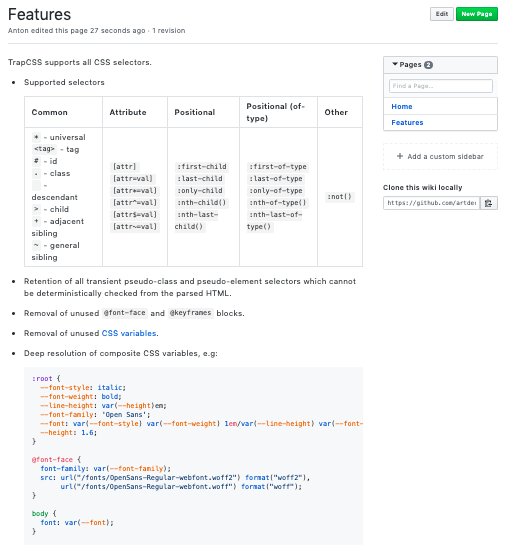
Features
This page contains description of supported features. I've simply copied the table from the source. A cool thing we can do, though, is to create an example file right in the Features directory itself, as it won't be read by Documentary that scans for md, markdown and htm[l] files only. We can then simply pass the relative path to the example:
- Deep resolution of composite CSS variables, e.g:
%EXAMPLE: ./example.css%Mind the indentation that is used with the example marker — it's needed so that GitHub recognises it as part of the list item.
Performance
This page contains some benchmark data for DropCSS. I'll keep it the same.
JavaScript Execution
This page is about opening a webpage in a headless browser to execute any dynamic JavaScript, which might manipulate DOM, so that the list of selectors is gathered after scripts are executed. I want to use the example, but the original depends on puppeteer which I think is redundant because if you have Chrome installed on your system, you can already open it. I don't want to download 80MB of a browser just for a simple script to be executed, so we'll simply install chrome-remote-interface and launch Chrome by hand. There's also chrome-launcher package however it's got 5 dependencies so until I've made a 0-dep fork, I'm not going to use it.
%EXAMPLE: ./execution, ../.. => trapcss%
%FORK-js ./execution%The example fork that spawns Chrome is going to be cached, so unless we make changes to the source code and recompile the package, we won't need to wait again for Chrome to start and load pages.
import idio from '@idio/idio'
import CDP from 'chrome-remote-interface'
import { spawn } from 'child_process'
import rqt from 'rqt'
import trapcss from '../..'
(async () => {
const { app, url } = await idio({
static: {
use: true,
root: 'example/www',
},
})
const chrome = await new Promise((r) => {
const p = spawn('/Applications/Google Chrome.app/Contents/MacOS/Google Chrome',
['--remote-debugging-port=9222', '--headless'])
p.stderr.on('data', (d) => {
d = `${d}`
if (/listening/.test(d)) setTimeout(() => r(p), 1000)
})
})
try {
const client = await CDP()
const { Network, Page, Runtime } = client
await Network.enable()
await Page.enable()
await Page.navigate({ url })
await Page.loadEventFired()
const { result: { value: html } } = await Runtime.evaluate({
expression: 'document.documentElement.outerHTML',
})
const { result: { value: links } } = await Runtime.evaluate({
expression: `[...document.querySelectorAll("link[rel=stylesheet]")]
.map((el) => el.href)`,
returnByValue: true,
})
await client.close()
await Promise.all(links.map(async href => {
const css = await rqt(href)
let start = +new Date()
const clean = trapcss({
css,
html,
})
console.log({
stylesheet: href,
cleanCss: clean.css,
elapsed: +new Date() - start,
})
}))
} catch (err) {
console.log(err)
} finally {
await app.destroy()
chrome.kill()
}
})()
I can also start Documentary in watch mode for Wikis also: yarn npm run wiki -- -p 'wiki pages'. Now it will watch for changes in both project and submodule directories, and force-push updates as necessary.
Accumulating Whitelist
There are some instructions on how to gather HTML selectors from multiple files, if CSS is reused across web pages. I'll copy the instructors and create an example also. When naming Wiki pages like Accumulating-a-Whitelist, hyphens become whitespace in titles.
-= INSTRUCTIONS =-
%EXAMPLE: ./whitelist, ../.. => trapcss%
%FORK-css ./whitelist%In watch mode, new examples will automatically be added to git tree also. Notice how I've imported the package from ../.. rather than from source. This is because I want to build documentation against the compiled code, so that I can be sure it's working. It's up to you whether you use source and compile target for documentation since ideally you'll be running test-compile so that they should produce identical results.
Special / Escaped Sequences
This page describes the problems with special characters in class names. I'll copy the description and give examples of how to overcome this difficulty. We can't have / in the page name, so we'll just call it Special AND Escaped Sequences. We'll want to place an example with HTML into the wiki folder, but to prevent Documentary from reading it, we'll make it hidden by adding a dot: .index.html.
Our example will also be cropped by using /* start/end example */ marker:import { join } from 'path'
import { readFileSync } from 'fs'
import trapcss from '../..'
const html = readFileSync(join(__dirname, 'index.html'), 'utf8')
const css = readFileSync(join(__dirname, 'index.css'), 'utf8')
/* start example */
// remap
let css2 = css
.replace(/\\:/gm, '__0')
.replace(/\\\//gm, '__1')
.replace(/\\\?/gm, '__2')
.replace(/\\\(/gm, '__3')
.replace(/\\\)/gm, '__4')
// more code
/* end example */This is so that we don't have to include admin set up of reading files in the example itself. Also despite me using import statements, and the file being a module, I can still use __dirname. This is perfect as there's absolutely no reason for Node to make everyone's life really difficult by removing this feature in .mjs files... We're here to make programs not worship standards.
In the end, there's another way to embed a fork:<fork lang="css">./</fork>This is equivalent to %FORK-css ./% and is a preferred method as Documentary is switching to components now.
Caveats & Acknowledgements
We'll keep those pages as is, since there are no examples.
- Not tested against or designed to handle malformed HTML or CSS
- Excessive escaping or reserved characters in your HTML or CSS can break TrapCSS's parsers- Felix Böhm's [nth-check](https://github.com/fb55/nth-check) - it's not much code, but getting `An+B` expression testing exactly right is frustrating. I got part-way there before discovering this tiny solution.
- Vadim Kiryukhin's [vkbeautify](https://github.com/vkiryukhin/vkBeautify) - the benchmark and test code uses this tiny formatter to make it easier to spot differences in output diffs.This should be it for Wiki. Now it's attached to our project and will always be available on GitHub.

License
I'd like to update our footer to include the information about the original license. I've chosen Affero for this project, so the footer at the moment looks like the following:
## Copyright & License
GNU Affero General Public License v3.0Let's include the original license:
## Copyright & License
GNU Affero General Public License v3.0
Original work on [_DropCSS_](https://github.com/leeoniya/dropcss) package
by [Leon Sorokin](https://github.com/leeoniya) under MIT license found
in [COPYING](COPYING).There are 2 standard files for a license, either LICENSE or COPYING. Since our AGPL is found in the former, we can include the original one in the latter. This is the convention I use for forked packages. I'll also update package.json to include the original license in the files field:
"files": [
"src",
"compile",
"types/externs.js",
"typedefs.json",
"COPYING"
]The LICENSE is always included by npm / yarn, so we don't need to specify it in there. We also want to publish the source code, so that the package can be compiled into other packages. If you're not publishing source code, remember to still include src/bin/index.js since it's defined in the bin field, and npm will not let you install the package if the file is missing (unlike yarn). typedefs.json will contain meta-information for package's types so that they can be linked to from other packages:
{
"_trapcss.trapcss": {
"link": "https://github.com/artdecocode/trapcss#trapcssconfig-config-return",
"description": "Parses the supplied HTML and CSS and removes\nunused selectors. Also removes empty CSS rules."
},
"_trapcss.Config": {
"link": "https://github.com/artdecocode/trapcss#type-config",
"description": "Options for the program."
},
"_trapcss.Return": {
"link": "https://github.com/artdecocode/trapcss#type-return",
"description": "Return Type."
}
}We'll come back to it in a second.

StdLib
We've done good job on implementation of API and CLI, their testing and documentation, and can publish the package now: yarn npm run publish. But before we do it, let's add a changelog line for the new version. Documentary comes with a cl binary that will ask for a new version of the package: yarn npm run cl, and create an appropriate link to compare versions.
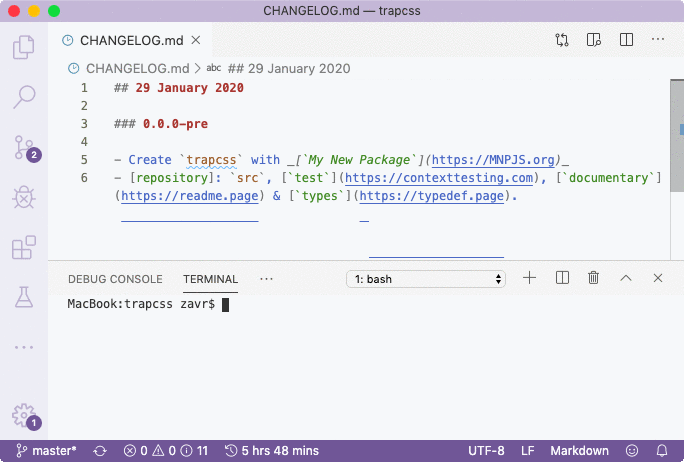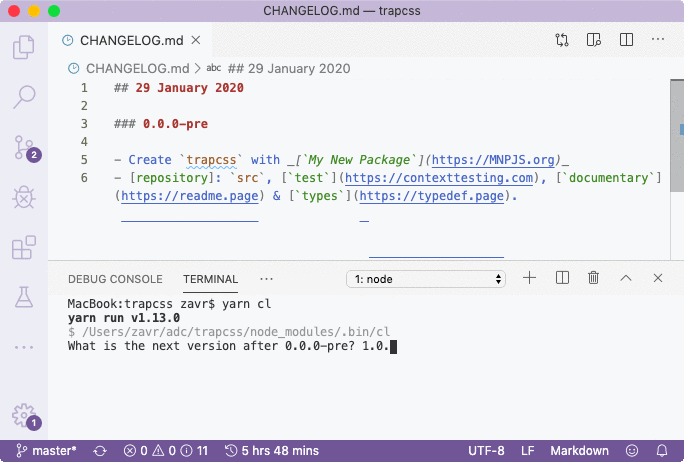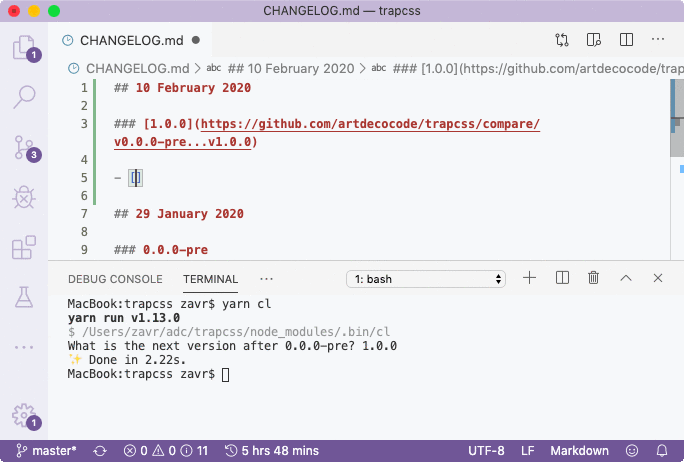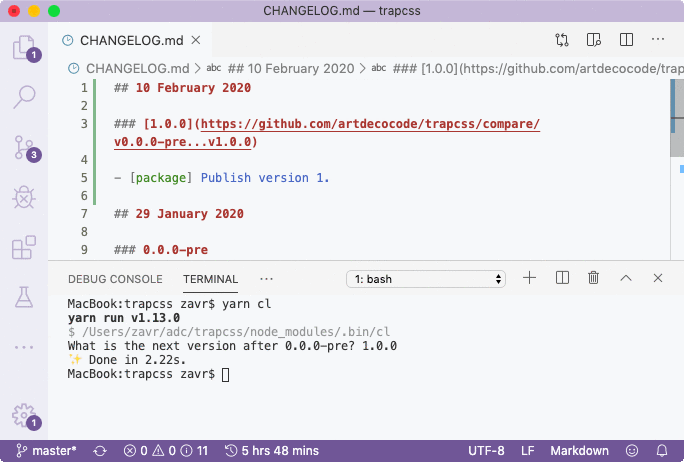
After publishing, I'll go ahead and make sure to push git tree with a new tag. The best way to do it is with git push --follow-tags command.
As I promised at start, we can incorporate TrapCSS into Splendid, a static website generator via its standard library. StdLib is a new concept that allows to place all dependencies into a single file and also compile them at the same time, so that the package receives access to all methods needs from dependencies, but doesn't have to install them. Such static linking is great to create neat packages without forcing your users to pull myriads of new dependencies they have no clue as to the purpose of. This will increase trust to your package and allow to produce great independent software products with full type checking, as compared to half-baked packages that can't go anywhere without 3rd party code. It also potentially increases security as it means you're reducing the attack scope by eliminating any dependencies that might become sabotaged in future (if their version is not fixed).Splendid's stdlib looks a bit like the following:
import '@externs/preact/types/externs'
import {
read, write, rm, exists, ensurePath, readDirStructure, readBuffer,
} from '@wrote/wrote'
import clone from '@wrote/clone'
import render from '@depack/render'
import aqt from '@rqt/aqt'
import cleanStack from '@artdeco/clean-stack'
import { ensurePathSync } from '@wrote/ensure-path'
import rexml from 'rexml'
import differently from 'differently'
import argufy, { reduceUsage } from 'argufy'
import Catchment, { collect } from 'catchment'
import controlStyle from '@lemuria/control-style'
import competent, { makeComponentsScript, writeAssets } from 'competent'
import { c, b } from 'erte'
import makePromise from 'makepromise'
import usually from 'usually'
import { confirm } from 'reloquent'
import spawn, { fork } from 'spawncommand'
import {
SyncReplaceable, Replaceable, makeMarkers, makeCutRule, makePasteRule,
replace,
} from 'restream'
import Pedantry from 'pedantry'
import compare from '@depack/cache'
import {
Bundle, getOptions, BundleChunks, getCompilerVersion,
} from '@depack/depack'
module.exports = {
'getOptions': getOptions,
'getCompilerVersion': getCompilerVersion,
'Bundle': Bundle,
'BundleChunks': BundleChunks,
// ... and so on
}I'm deliberately giving the full list of imports so that you can understand the meaning behind STDLIBs. They are literal libraries for your big projects. The fact is that you don't want to fully compile huge projects because it's time consuming and unnecessary actually, since their source code isn't going to be used in other packages. They are standalone pieces of software, so it's ok to just build them. But to eliminate dependencies, we need an stdlib. The trick is then to rename all imports from 3rd party packages that you had in source code, to point to the stdlib instead.
// was
import { join } from 'path'
import { read, write, ensurePath, exists } from '@wrote/wrote'
import { Bundle, getOptions, BundleChunks } from '@depack/depack'
import { c } from 'erte'
import compare from '@depack/cache'
import { deepStrictEqual } from 'assert'
import { getDates } from '../'
import { resolveInternal } from '../'
// becomes
const { join } = require('path');
const { read, write, ensurePath, exists } = require('../../../stdlib');
const { Bundle, getOptions, BundleChunks } = require('../../../stdlib');
const { c } = require('../../../stdlib');
const { compare } = require('../../../stdlib');
const { deepStrictEqual } = require('assert');
const { getDates } = require('../');
const { resolveInternal } = require('../');This is achieved when we run ÀLaMode on the source code with build environment
{
"b": "yarn-s src jsx",
"src": "alamode src -o build -s -i bin/.eslintrc,js,components,stdlib.js -j -p -m --env build",
"jsx": "alamode src/components -o build/components -s -i .eslintrc -j -E --env build",
}Splendid includes some server-side as well as client-side JSX components, so I need 2 scripts, one for SSR, and second for the browser so that Preact is imported as an extern rather than package (-E flag). Let's just focus on the src script:
- src, the input directory for compilation.
- -o build, where to put transpiled files to.
- -s, disable source maps (they're not needed at all since the transpiler is really good at preserving the style of code and just renames imports into requires).
- -i bin/.eslintrc,js,components,stdlib.js, those files will be ignored. We don't need to build the stdlib.js file itself as it's only for Closure.
- -j, enables JSX transpilation.
- -p, adds Preact pragma for JSX files.
- -m, transpiles modules into requires (which is disabled by default for JSX).
- --env build, use the build environment, to rename StdLib.
The environment is defined in the .alamoderc.json file:
{
"env": {
"test-build": {
"import": {
"replacement": {
"from": "^((../)+)src",
"to": "$1build"
}
}
},
"build": {
"import": {
"stdlib": {
"path": "stdlib",
"packages": [
"argufy", "catchment", "clearr", "erte",
"forkfeed", "makepromise", "mismatch", "rexml", "@wrote/wrote",
"@wrote/clone", "@wrote/ensure-path", "pedantry", "@depack/cache",
"usually", "resolve-dependency", "spawncommand", "restream",
"@depack/render", "@rqt/aqt", "reloquent", "differently",
"which-stream", "@wrote/read-dir-structure", "competent",
"@lemuria/control-style", "@depack/depack", "@artdeco/clean-stack"
]
},
"alamodeModules": ["alamode", "@wrote/read", "@wrote/write",
"@wrote/clone", "@lemuria/popup", "@depack/render",
"@idio/frontend", "@goa/koa", "@idio/websocket", "differently",
"@artdeco/clean-stack",
"competent", "@idio/idio", "closure-stylesheets-java",
"@lemuria/control-style"]
}
}
}
}It's pretty large as it contains the list of all modules that we want to rename (alamodeModules is a separate thing, which disables __esModule check when importing default exports). Under stdlib property, we specified the path to the library, and all packages that should be renamed. Now it's time to compile stdlib.
I'm going to install trapcss as a dev dependency (since it will be compiled into stdlib statically) and include it in the appropriate places.// src/elements/bootstrap-css/run_template.jsx
import trapcss from 'trapcss'I can also validate that there are autocompletion hints.
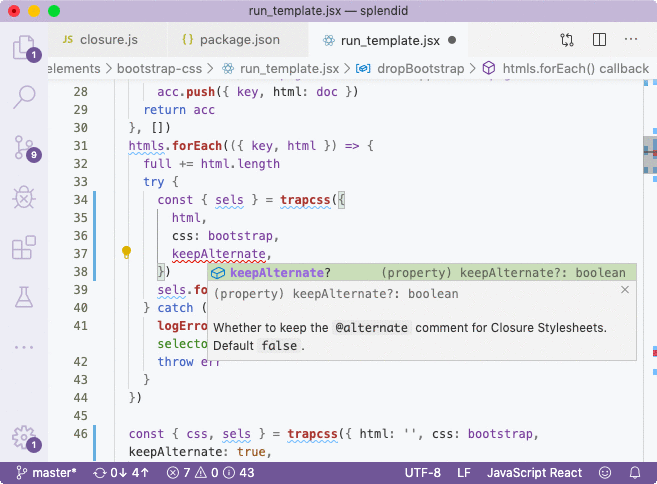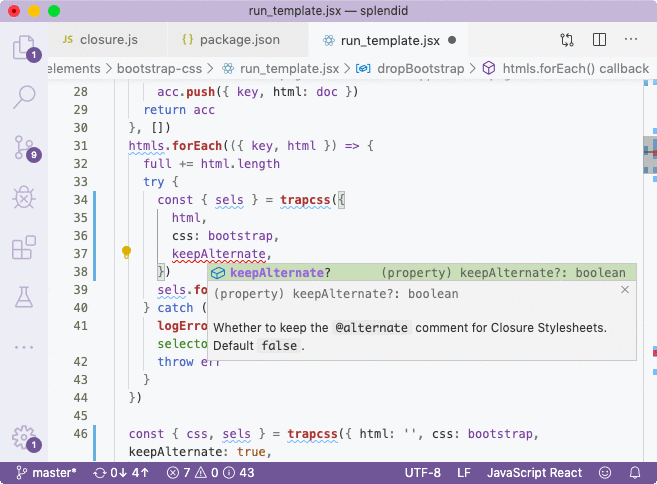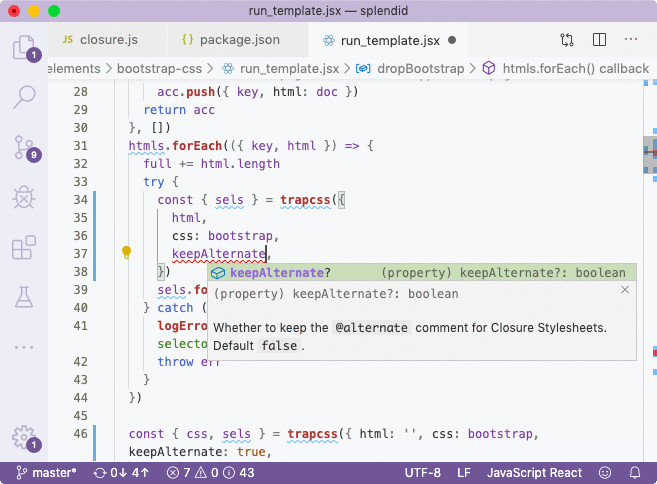
The src/stdlib file is the entry point that will be compiled. module.exports is a known object defined in externs and by assigning properties to it using quotes, we prevent renaming of its properties.
// src/stdlib.js
// ... prev imports
import trapcss from 'trapcss'
module.exports = {
'trapcss': trapcss,
'getOptions': getOptions,
// ...
}Now update the env:
{
"build": {
"import": {
"stdlib": {
"path": "stdlib",
"packages": [
"...all-other-packages", "trapcss"
]
}
}
}
}
}And use the stdlib script:
{
"stdlib": "depack src/stdlib -o stdlib/index.js -a -c -p -s --source_map_include_content",
}It will run Depack with pretty much standard Node.JS compilation configuration, that also includes source code in source maps, so that we can debug it when necessary. It will increase the package size by about 350KB, so it's optional. An alternative for debugging is to clone package locally and link to it from the project which is being debugged.
After stdlib is compiled, I can build the project again, and see the changes:// was
let dropcss = require('dropcss'); if (dropcss && dropcss.__esModule) dropcss = dropcss.default;
// now 🎉
const { trapcss } = require('../../../stdlib');Using this technique, I've reduced the number of dependencies in my project (by 1 with TrapCSS, but by about 50 considering all other packages). This method is really great for modern package development that NodeTools facilitate.
As the final step, let me explain the purpose of typedefs.json. Because we want to link between documentation pages, we want to know where each type is described: it could be either in the main readme file, or somewhere in Wiki. This file remembers the exact location of where the type is described.Splendid has got some documentation about dropping types:
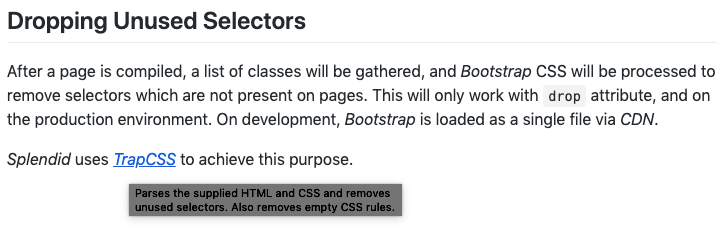
## Dropping Unused Selectors
After a page is compiled, a list of classes will be gathered, and
_Bootstrap_ CSS will be processed to remove selectors which are not
present on pages.
<include-typedefs>trapcss</include-typedefs>
_Splendid_ uses <link type="_trapcss.trapcss">_TrapCSS_</link>
to achieve this purpose.By calling the include-typedefs component, we added the information of our types to Documentary. After that, we can use the link component to insert a link to this type. Obviously, _trapcss.trapcss is a method and not a type, but if Splendid at any point was extending any type from TrapCSS (e.g., its config), or used a property from its own config to be of TrapCSS config (e.g., { trapcss: {/* trap config */ } }), the correct link would appear in the documentation. This makes the process robust since there's no manual work required and prevents outdated linking.
I think that's about it for advanced topics, so please feel free to leave comments and ask questions. Part III will be about creating a website for the project with Splendid, but in due time.
Loading sharing buttons...

Comments