
Pages
- NodeTools: Node.JS Stack
- Quick Start To NodeTools
- TrapCSS: NodeTools Tutorial
- TrapCSS 2: Advanced NodeTools
- Web Development With NodeTools
- Babel: When Open Source Is Not Free Sofware
- Discussion for NodeTools
Stack
Web Software
Misc
TrapCSS: NodeTools Tutorial
There are CSS frameworks such as Bootstrap that allow to create great layouts quickly, however their size might be quite large. This point is worth considering because CSS is loaded in a blocking fashion: the browser will have to wait before all CSS is loaded to render a web site, so large external stylesheets actually slow down page render by postponing first meaningful paint. This affects usability and even search engine ranking negatively. In many cases, a lot of CSS can be "dropped" from frameworks' compiled code by leaving only those selectors that are present on a page, or multiple pages. This technique corresponds to the "Defer unused CSS" Lighthouse warning.

One of the packages that is able to do it quickly is called DropCSS, developed by Leon Sorokin. It's notable for its speed, simplicity and the amount of bytes that can shaved off the CSS. However, for our use case it was not perfect: it strips comments and does not allow to keep arbitrary annotations, such as /* alternate */ which is needed for Closure Stylesheets. Closure Stylesheets is an optimiser of CSS that can minify and put styles together. Art Deco uses it for Splendid, a static website generator. By collecting selectors across all pages on a generated website, we're able to drop unused Bootstrap rules, and then merge Bootstrap with other styles so that a single, small CSS file is served to visitors quickly, with Bootstrap size reduction of around 95%.
But Bootstrap contains rules that repeat the CSS properties, e.g.,:abbr[title],
abbr[data-original-title] {
text-decoration: underline;
-webkit-text-decoration: underline dotted;
/* @alternate */
text-decoration: underline dotted;
/* ^ repeated use, need alternate */
}We needed to annotate Bootstrap with the /* alternate */ marker so that the CSS compiler doesn't throw an error. A simple proposed solution to prevent stripping such comments was suggested in form of a PR to DropCSS package owner, however was rejected as being too narrow of a use case. Therefore, we decided to fork his project and use its source code to create a professional Node.JS package that would also provide JSDoc annotations, could be tested with context testing, and is ready to be compiled into other packages, such as Splendid itself, so that it's linked statically instead of dynamically as permitted by the original MIT license.
This tutorial walks through the process of upgrading a package to use NodeTools stack with explanation of advantages of using the tools from the stack in creating modern packages. You might want to read the quick start guide first for some details about the standard routine.
TrapCSS on GitHub:
GitHub⭐️ 1
TrapCSS on NPM:
TrapCSS1.2.0

MNP
The very first step is to spawn a new package using mnp binary. Instead of forking the repo, I will create a new package so that its structure adheres to NodeTools' recommendations. My default organisation is artdecocode on GitHub and I keep projects in the ~/adc folder. Additionally, I've made a number of other orgs, such as dpck, a-la for scopes of other projects that are made up of many packages — organising your GitHub workspace and the home dir by orgs is a convenient method that allows to maintain different settings for different organisations and keep them semantically grouped. When you're ready to grant permissions to other developers to maintain your packages, you can do it on per-org basis. For a standard Node.JS package, I'll just use adc.
cd adc
# mnp --init (if init was not done yet)
mnp trapcss -nI've already configured mnp prior to creating a package, therefore all settings are already recorded in the .mnprc file. I pass the package name to the binary, together with the -n flag, which means --no-scope: because settings contain a scope (@artdeco), I want to skip it in this particular case. MNP then asks me questions about the new package:
# trapcss
Description: Removes unused selectors from CSS files to achieve maximum optimisation. Can be used as an API function or with CLI.
Generating repository...
Starring...
⭐️ Created and starred a new repository
https://github.com/artdecocode/trapcss
Cloning into '/Users/zavr/adc/trapcss'...
Setting user Anton<anton@adc.sh>...
With binary [y/n]: [y]
Build or compile: [compile]
License: [agpl-3.0]
Init Github Wiki [y/n]: [y]
Homepage: [https://github.com/artdecocode/trapcss#readme] https://art-deco.github.io/trapcss
Keywords (e.g., artdecocode, trapcss): css, minifier, web, browser
Please go to https://github.com/artdecocode/trapcss/wiki/_new
to create the first page and press enter when done. (y/n): [y]
Cloning into '/Users/zavr/adc/trapcss/wiki.git'...
Setting topics...
Initialised package structure, pushing...
yarn install v1.13.0
✨ Done in 2.67s.
Created a new package: trapcss.I've answered questions in the following way:
- With binary: true, because I'll want to create a node executable to run from the CLI to drop selectors from CSS files based on HTML files.
- Build or compile: compile, because I want to create a library compatible with Closure so that it can be compiled into Splendid later.
- License: agpl-3.0, my personal preference that prevents exploitation of my work. We'll keep the original MIT copyright notice in the source code.
- Init Github Wiki: y, we'll want to create wiki pages with discussion about certain use cases, such as using multiple HTML files to gather selectors list.
- Homepage: https://art-deco.github.io/trapcss, I update the default homepage that points to the repo readme on GitHub, because I'll want to create a website for the package with a demo.
- Keywords: css, minifier, web, browser, some tags for GitHub topics and NPM keywords.
I'm then asked to navigate to GitHub to create the first Home wiki page. This needs to be done manually since GitHub does not provide API routes for automation of this procedure. After I've done this, MNP will install dependencies automatically, depending on your manager setting in MNP (either yarn or npm) and you'll have either package-lock.json or yarn.lock files. Now the template is fully populated with settings and personalised, a new tag v0.0.0-pre is added to git tree and the initial commit is pushed. My package is found in trapcss folder and MNP opens VSCode automatically.

Upgrading Source Code
As the next step, I'll just download the ZIP archive from DropCSS with the source code, and open finder to copy all files from source into my new package.
The original source is using CommonJS however NodeTools allow to program using ECMA modules with a 0-dependency regex transpiler, so we want to update the source code from require into imports."use strict";
const { parse: parseHTML } = require('./html');
const { parse: parseCSS, generate: generateCSS,
SELECTORS, stripEmptyAts } = require('./css');
const { some, matchesAttr } = require('./find');
const { postProc } = require('./postproc');
const { LOGGING } = require('./env');This can be achieved easily by running the transpiler in -r mode:
MacBook:trapcss zavr$ yarn alamode src -rIt will scan the src dir recursively, updating all files in there. Only yarn supports running binaries from local node_modules with yarn bin-alias to execute aliases installed in the project folder within node_modules/.bin (which is why we prefer it), but for npm, the alanode script has also been defined, so you can call npm run alanode too if you want to execute any module that needs transpiling, such as examples.
When trying to simply check that all imports are updated correctly by running yarn npm run alanode src/dropcss that only executes all require calls without actually running the program, I see an error to do with the following:// src/find.js
function some(nodes, m) {
return nodes.some(node => find(m, {
idx: m.length - 1,
node
}));
}
export { matchesAttr };
export const some = (nodes, sel) => {
return some(nodes, Array.isArray(sel) ? sel : parseSel(sel));
};The error says:
MacBook:trapcss zavr$ yarn alanode src/dropcss.js
/Users/zavr/adc/trapcss/src/find.js:205
const some = (nodes, sel) => {
^
SyntaxError: Identifier 'some' has already been declaredThis is because after updating to imports, we acquired a name conflict. This is fixed simply by renaming the original function into _some and calling it from the export:
// src/find.js
function _some(nodes, m) {
// ...
}
export const some = (nodes, sel) => {
return _some(nodes, Array.isArray(sel) ? sel : parseSel(sel));
};In addition, I don't use semicolons therefore I'll quickly fix that with ESLint. ESLint should be installed globally on the system since it's a huge binary and there's no point in installing it for each single package. If you have your own eslint config, you need to fork the template from mnpjs/package, define your config in there, and modify the .mnprc settings file to point to your forked template.
MacBook:trapcss zavr$ eslint --fix srcAs the last step for styling, I want to get rid of all "use strict" directives on top of each file, by a simple search and replace in VSCode: "use strict"\n\n -> "". Finally, I want the entry to the library be located at src/index.js instead of src/dropcss.js, therefore I copy the typedef from index.js, delete the file, and rename dropcss.js into index.js.
// copy typedef as needed for next step
/**
* @suppress {nonStandardJsDocs}
* @typedef {import('../types').trapcss} _trapcss.trapcss
*/Now I can commit all new source code into the git tree, and start testing/documenting the library.

Adding Types
After we've copied the typedef, we'll want to write types that are relevant for our program. The main method accepts a hashmap config, so we'll document its structure in types/index.xml.
<types namespace="_trapcss">
<record name="Config" desc="Options for the program.">
<prop string name="html">
The input HTML.
</prop>
<prop string name="css">
The CSS to drop selectors from.
</prop>
<prop boolean name="keepAlternate" default="false">
Whether to keep the `@alternate` comment for
Closure Stylesheets.
</prop>
<fn name="shouldDrop" opt return="boolean">
<arg string name="sel">The selector to check.</arg>
Whether _TrapCSS_ should remove this selector.
The `shouldDrop` hook is called for every CSS selector
that could not be matched in the html. Return `false`
to retain the selector or `true` to drop it.
</fn>
</record>
<type record name="Return" desc="Return Type.">
<prop string name="css">
The dropped CSS.
</prop>
<prop type="!Set<string>" name="sels">
The used selectors.
</prop>
</type>
</types>We're using the _trapcss namespace to be able to name our config as _trapcss.Config and distinguish it from other packages' configs that can be defined with the same name. The namespace is the feature of VSCode that we use to our advantage, and it's not much different from standard typedefs, only that names of types are preceded with the _ns. We also use _ underscore as the convention for namespaces' titles, otherwise there might be conflicts between them and some functions in the source code.
There are 3 main types of types: records, interfaces and constructors. The key point to remember is that records are used for configs and other simple objects passed between programs, while interfaces are used to describe methods and properties on classes, which are then annotated with /* @implements {_ns.Type} */ in the source code. Unfortunately, VSCode doesn't understand the implements notation and will not allow to "put meat" or grow implementation on the interface defined like that while providing hints during implementation process, but this notation is used to enable Closure Compiler type checking. Some examples of @implements can be found in the Goa server./**
* @implements {_goa.Application}
*/
export default class Application extends EventEmitter {
/**
* Initialize a new `Application`.
* @param {!_goa.ApplicationOptions} options
*/
constructor(options = {}) {}
// if VSCode understood @implements, we wouldn't have to
// specify the type of the argument in @param as it could
// be deducted from the interface type ;)
}The <type record>...</type> block can be simplified to <record>...</record>, same with interface. Constructors are used very rarely.
If a type is defined without record/interface attribute, it becomes the simplest type in the Closure type system called a structural interface, for example, { prop: string, prop2: (number|undefined) }. An object like that is not nullable — since Closure tries to make JavaScript similar to Java, type nullability is a thing. More complex types, such as records and interfaces are nullable, whereas structural interfaces are not. Here's some more documentation on types. Therefore, when we use a record that is not expected to be nullable, we'll want to add ! in front of it, as shown below.Not only do we document config and return types in XML, but also the actual API contract of the library, which is placed in the types/api.xml file and describes all available methods that can be imported from our Node.JS library.
<types namespace="_trapcss">
<method name="trapcss" return="!_trapcss.Return">
<arg name="config" type="!_trapcss.Config">
The options for _TrapCSS_.
</arg>
Parses the supplied HTML and CSS and removes
unused selectors. Also removes empty CSS rules.
</method>
</types>It's the core principle of NodeTools to use XML to store types. You can view it as the design stage that provides a language- and tool-agnostic way to document our software, whereas JS is used for implementation later. We can reuse types for any purpose, such as creating documentation as shown later. Because types are not written in a complex proprietary format like .ts (TypeScript typings), anyone can make software that uses a simple XML parser to extract types, and build their own schema upon the existing one.
Typedefs
The next thing we want to do is to generate typedefs for VSCode so that we can get working on the source code implementation. The template we used with MNP already has the set up ready for that, we just call yarn npm run d. This command will update typedefs in types/index.js, which are then imported in our source code via the @typedef {import('../types')} JSDoc. yarn npm run d actually spawns multiple commands, including template, d1 and externs. It will run yarn-snpm-s for serial execution of all 3 of these commands in series.
export {}
/* typal types/api.xml namespace */
/**
* @typedef {_trapcss.trapcss} trapcss Parses the supplied HTML and CSS and removes
unused selectors. Also removes empty CSS rules.
* @typedef {(opts: _trapcss.Config) => _trapcss.Return} _trapcss.trapcss Parses the supplied HTML and CSS and removes
unused selectors. Also removes empty CSS rules.
*/
/**
* @typedef {import('..').Config} _trapcss.Config
*/
// 1) add the return import
/**
* @typedef {import('..').Return} _trapcss.Return
*/The config is imported from the main JS of the package, which is kept in compile/index.js. We'll come back to that later, but we also need to import (1) the return type manually, as the template's function simply returned a string before. To check that it's been imported correctly, we simply hover over the top declaration.
This types/index.js file is only used for development purposes, and it's real aim is to provide an annotated function type that is then imported in the source code. We come back to the source code, find our implementation and annotate it with the type:
// src/index.js
// adding @type
/**
* @type {_trapcss.trapcss}
*/
function dropcss(opts) {
let log, START
if (LOGGING) {
START = +new Date()
log = [[0, 'Start']]
}
// ... implementation
}Make sure to remember to copy across that typedef with import:
/**
* @suppress {nonStandardJsDocs}
* @typedef {import('../types').trapcss} _trapcss.trapcss
*/The @suppress is needed because Closure Compiler cannot parse imports in typedefs, so that we skip this warnings. However, this function type is also generated in externs which are fed to the Compiler when compiling packages, so that it will be aware of the type. When using namespaces, we need to be consistent with their namings: if we simply imported trapcss instead of _trapcss.trapcss, we'd receive access to VSCode JSDoc, but the compiler wouldn't know about the trapcss type without the namespace.
The advantage of such annotation is that the comments will be lost during compilation anyway, so we don't have to waste time maintaining them in the source code itself. If we need to update the API contract, we go to the XML file, make changes there, and generate new annotations and externs using yarn npm run d command.
Externs
When compiling packages, we need to learn a new concept called externs — a separate JS file that includes typedefs in a special format understood by Closure Compiler that provide type information to it. Externs look like the following:
/**
* @fileoverview
* @externs
*/
/* typal types/index.xml externs */
/** @const */
var _trapcss = {}
/**
* Options for the program.
* @record
*/
_trapcss.Config
/**
* The input HTML.
* @type {string}
*/
_trapcss.Config.prototype.html
/**
* The CSS to drop selectors from.
* @type {string}
*/
_trapcss.Config.prototype.css
/**
* Whether to keep the `@alternate` comment for
* Closure Stylesheets. Default `false`.
* @type {boolean|undefined}
*/
_trapcss.Config.prototype.keepAlternate
/**
* Whether _TrapCSS_ should remove this selector.
* The `shouldDrop` hook is called for every CSS selector
* that could not be matched in the html. Return `false`
* to retain the selector or `true` to drop it.
* @type {(function(string): boolean)|undefined}
*/
_trapcss.Config.prototype.shouldDrop = function(sel) {}
/**
* Return Type.
* @record
*/
_trapcss.Return
/**
* The dropped CSS.
* @type {string}
*/
_trapcss.Return.prototype.css
/**
* The used selectors.
* @type {!Set<string>}
*/
_trapcss.Return.prototype.sels
/* typal types/api.xml externs */
/**
* Parses the supplied HTML and CSS and removes
unused selectors. Also removes empty CSS rules.
* @typedef {function(_trapcss.Config): _trapcss.Return}
*/
_trapcss.trapcss
The purpose of externs is to provide type information for Closure Compiler. When using advanced compilation, which we are, property names on objects will get renamed, which is not good when we publish the package with declared config type. By generating an extern, we're making sure that its properties are not renamed. package.json file also adds the "externs": "types/externs.js" field, so that 3rd party packages that want to compile our package into themselves, will receive access to its types for Closure. This is how NodeTools infrastructure works.
Depack includes externs for Node 8 API. We haven't upgraded them to newer versions, and some namespaces, like tls might still produce warnings during compilation. You can check out the repository by the link, modify externs, and submit a PR. On the other hand, for any additions to Node externs, you can simply type them in the types/externs.js file, e.g.,/* typal types/index.xml externs */
// auto-generated externs
// manual externs
/** @type {string} */
process.env.MY_ENV_VAR
/**
* @constructor
* @param {{ quantumLocation: boson }} options
*/
stream.SuperDuplexNode16 = function(options)
/**
* @constructor
* @param {!fs.Entanglement} ent
*/
stream.SuperDuplexNode16.prototype.open = function(ent)There are also externs for 3rd party libraries, for example, for Preact that we've created. Refer to it as an example for front-end externs. If you want to submit externs for some library, please open an issue with a link to your externs and they'll get published on the @externs/your-extern scope from within the GitHub externs org. You might want to search online for existing externs first, or send PRs to packages that you use in your projects with generated externs and externs field in package.json. In other words, there are 2 strategies: to publish externs as separate packages, and import them in code, which looks pretty cool, or simply have them in the same package and import from types/externs.js file.
The /* typal types/index.xml */\n\n marker always requires 2 new lines after it (even if it's at the end of the file). Please remember that.
/* typal types.xml */
// ^ make sure a new line always follows the typal marker.Accessing Properties
Our standard is to use destructuring on the config to extract its properties for use in the program first thing. If the config was not compulsory, we'd also add the default value to the config argument: function (config = {}), but it's not the case here. When doing this, we also receive the type of the property, so that we're able to expand hints if we need to perform operations on these symbols.
On the screenshot above, you can see how the IDE provides me with autocompletion hint when I'm trying to get access to the .length property, for example to check that HTML is not empty. This is essential for developer experience of the person who's coding the package, so by simply importing the type, we were able to achieve this productivity without full JSDoc with @param {Object} comments. Sadly, VSCode does not show the description of the property, otherwise it'd be really perfect, but maybe they can do it in the next version.
So we just update the source code to pass destructured properties, and the new keepAlternate additional property to the parseCSS method. The keepText second argument for parseHTML is not even accepted by this function, but we'll remove it in the second part.// const H = parseHTML(opts.html, !opts.keepText) =>
const H = parseHTML(html, !keepText)
// const shouldDrop = opts.shouldDrop || drop =>
// default is now assigned via destructuing
// above { shouldDrop = drop, ... } = opts
// let tokens = parseCSS(opts.css) =>
let tokens = parseCSS(css, keepAlternate)

Initial Documentation
Before we continue to adding actual logic to allow to preserve alternate comments, let's add some documentation to TrapCSS. The docs are kept in the documentary folder and are split by files, which are put in order by documentation software. The index.md and footer.md files in each of the inner dirs always go first and last respectively. The root index.md already contains the description which was placed in there by MNP. It also has the installation snippet and table of contents. But we can add some more text from the forked package to describe what the software will do, and some additional links.
<!-- documentary/index.md -->
```sh
yarn add trapcss
npm install -D trapcss
```
## Introduction
_TrapCSS_ takes your HTML and CSS as input and returns only
the used CSS as output. Its custom HTML and CSS parsers are
highly optimized for the 99% use case and thus avoid the
overhead of handling malformed markup or stylesheets, ...
<kbd>📙 [READ WIKI PAGES](../../wiki)</kbd>
%~%
%TOC%
%~%We'll give a link to wiki which contains some more detailed information, which will be compiled later. We use section breaks like %~% which insert visual separators between sections.
The api/index.md also contains essential data for generation of the README file:<typedef method="trapcss">types/api.xml</typedef>
<typedef>types/index.xml</typedef>
%EXAMPLE: example, ../src => trapcss%
%FORK example%Documentary uses components and markers. The typedef component allows to place method headings (when the method= attribute is given) and markdown tables with record descriptions.
The typedefs will result in the following generated text:## <code><ins>trapcss</ins>(</code><sub><br/> `opts: Config,`<br/></sub><code>): <i>Return</i></code>
Parses the supplied HTML and CSS and removes
unused selectors. Also removes empty CSS rules.
- <kbd><strong>opts*</strong></kbd> <em><code><a href="#type-config" title="Options for the program.">Config</a></code></em>: The options for _TrapCSS_.
__<a name="type-config">`Config`</a>__: Options for the program.
| Name | Type | Description | Default |
| ------------- | --------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------- |
| __html*__ | <em>string</em> | The input HTML. | - |
| __css*__ | <em>string</em> | The CSS to drop selectors from. | - |
| keepAlternate | <em>boolean</em> | Whether to keep the `@alternate` comment for<br/>Closure Stylesheets. | `false` |
| shouldDrop | <em>(sel: string) => boolean</em> | Whether _TrapCSS_ should remove this selector.<br/>The `shouldDrop` hook is called for every CSS selector<br/>that could not be matched in the html. Return `false`<br/>to retain the selector or `true` to drop it. | - |
__<a name="type-return">`Return`</a>__: Return Type.
| Name | Type | Description |
| --------- | --------------------------- | ------------------- |
| __css*__ | <em>string</em> | The dropped CSS. |
| __sels*__ | <em>!Set<string></em> | The used selectors. |which looks like on the screenshot below:

The heading is generated from the first typedef, and type tables from the second one. Any types that are referenced on the page will be linked, such as the Config type of opts in the function's description. To generate README, we run the yarn npm run doc command, and the doc script consists of: doc [documentary] ...
- -o README.md: the output file
- -n _trapcss: the root namespace
- -a: generate annotations into typedefs.json
- -d: verbose debug logging
The default location for input is documentary but it can be changed. Method headings can also be customised using your own <method> component put into .documentary folder. Once again, the dev process for documentation is fully automated and provides customisation strategies so you can express your own creativity with custom method headings. Custom type tables via JSX components will be supported in future versions also. Submit an issue if you run into difficulties during customisation.
Documentary is not a simple JSDoc to HTML generator. It's an advanced piece of software that allows to compile full, quality documentation from examples, markdown and type information. It's there to make you effective at writing READMEs and automate the process as much as possible, but you're in control of how your docs look like.Examples To Outputs
The second most useful feature of NodeTools after the compiler is the ability to automatically place examples into README, and compute their output which is also added to README. We use the %EXAMPLE% marker to reference the example file that comes from the examples folder. All paths will be resolved in Node style conventions, i.e. by looking up the index.js file if a directory is passed, so we can simply reference example dir. Let's create a sample usage of our program with some HTML and CSS to see if it works.
%EXAMPLE: example, ../src => trapcss%When placing examples, we can actually rename the local import into the package name so it looks professional to our users who can then just copy and paste the example into their own code.
import trapcss from '../src'
let html = `
<html>
<head></head>
<body>
<p>Hello World!</p>
</body>
</html>
`
let css = `
html {
background: yellow;
/* @alternate */
background: green;
}
.card {
padding: 8px;
}
p:hover a:first-child {
color: red;
}
`
const whitelist = /#foo|\.bar/
let dropped = new Set()
let cleaned = trapcss({
html,
css,
shouldDrop(sel) {
if (whitelist.test(sel))
return false
else {
dropped.add(sel)
return true
}
},
})
console.log(cleaned.css)
console.error(dropped)To test the example before actually compiling docs, we can call alanode which is a simple proxy process to Node with a require hook that transpiles imports. It's executed via the package manager: yarn npm run alanode example/.
MacBook:trapcss zavr$ yarn alanode example/
html{background: yellow;background: green;}
Set { '.card', 'p:hover a:first-child' }The example is working fine, so we can embed it. If at any point you see blank code blocks in your READMEs, try executing examples with alanode to check for any errors. We're going to modify the markdown file in the following way:
<!-- was: -->
<!-- %FORK example% -->
<!-- now: -->
%FORK-css example%
%FORKERR-js example%It's possible to fork a single process and then pipe both stdout and stderr streams into the documentation. The language of the fork is also given within FORK-{lang} which means that stdout will be printed as CSS and stderr as JS code blocks. Forked JS modules are also cached so that if the example and/or any of its dependencies (src files, or imported packages' versions) changed, data will be read from cache which saves a lot of time for more complex programs that might call external APIs or system IO. Specifying language enables syntax highlighting on GitHub so that docs will look neat.

When documenting code, we can keep Documentary running with the yarn npm run doc -- -p "commit message" command. It will watch for changes in the source folder, as well as any assets such as examples, automatically replace the last commit when changes are detected, and force push the new git tree. So we can work on examples and styling of the docs, and immediately see updates on GitHub (after a page refresh).
At this point, without having written any tests, we already confirmed that our package is working correctly, because we managed to execute an example and place its output into the README file. This is called using documentation for quality assurance, as it lets us see the expected output. If the output was different from the one we wanted (or there was no output at all), we'd realise that by the time our documentation is uploaded on GitHub (in automatic mode) or in git diffs (when running a single yarn npm run doc command).

Creating Tests
Tests for the original packages were written for Mocha testing framework, but we need to update them into Zoroaster context-testing specs and masks. Let's take the first test suite and have a look at its structure:
const dropcss = require('../../src/dropcss.js')
const assert = require('assert')
describe('Context-free, unary selector', () => {
let html, css
describe('*', () => {
it('should retain present', function() {
let { css: out } = dropcss({
html: '<div></div>',
css: '* {a:b;}',
})
assert.equal(out, '*{a:b;}')
})
})
describe('<tag>', () => {
it('should retain present', function() {
let { css: out } = dropcss({
html: '<div></div>',
css: 'div {a:b;}',
})
assert.equal(out, 'div{a:b;}')
})
it('should drop absent', function() {
let { css: out } = dropcss({
html: '<div></div>',
css: 'span {a:b;}',
})
assert.equal(out, '')
})
})
describe('#id', () => {
it('should retain present', function() {
let { css: out } = dropcss({
html: '<div id="a"></div>',
css: '#a {a:b;}',
})
assert.equal(out, '#a{a:b;}')
})
it('should drop absent', function() {
let { css: out } = dropcss({
html: '<div id="a"></div>',
css: '#b {a:b;}',
})
assert.equal(out, '')
})
})
})We can see that each time the logic is pretty much the same: we use the <div></div> html as HTML string for first cases, but change it to <div id="a"></div> for ID selector tests, then manipulate some CSS from test to test and expect the result to be equal to certain values. All tests are written within describe and it blocks for Mocha which has been in use for testing both back-end and front-end applications for a long time. In contrast, NodeTools, being an entirely new stack for professional web development, includes a brand new testing framework called Zoroaster that is really low-weight, yet contains more features out of the box than its main competitors and introduces new concepts in Quality Assurance such as mask- and context-testing.

Mask Testing
Tests like the ones shown above are perfect candidates for mask testing — a new type of tests where using a template called test mask we generate many specs at runtime based on multiple input-to-output mappings that come from a separate file called mask result. If you've ever used a loop to call describe and it methods by hand, you'll be familiar with the concept of dynamic test suite construction. Zoroaster provides an official standard way to do that, and coins the term mask testing to name this process.
Each program or method is just a state machine that maps inputs to outputs on a problem space. While testing, we control inputs, and observe outputs, which are then asserted on for correctness of the algorithm. Therefore specs that we write, allow us to mask the problem space using inputs as variables.Consider the example below (move mouse over the black screen to discover the problem space): one way to interpret the graph is as of a function that accepts 2 variables (x1 and x2) and outputs y according to inputs (in real life though, these are just data points in a 3D space). To know this Y position, we need to execute the function and see what output it produces. Such machine learning models as a regression model allow to approximate real-world functions using planes, but the point of this example is that a mask is a collection of specs, where each spec is a data point. The mask is that circle you see on a diagram, that envelops a number of crosses, i.e. exact data points (specs) that we collect by running tests. The more specs we generate, the fuller picture we get. Ideally, we want to test all possible inputs including edge cases, but practically we just want to meet our requirements.
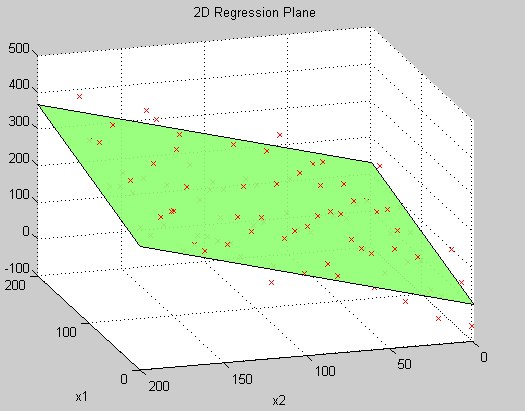
A spec is a single data point on the algorithm's problem space, whereas a mask is a collection of such points. Mask testing allows to generalise spec creation process and provides a broader strategy for quality assurance.
Pure functions will always produce the same result, so we want to program mostly in functional style to avoid side effects in script scopes that make mapping non-deterministic. But no need to worry as it's probably what you've been doing with JS anyway. However with Mocha, it's become almost an anti-pattern to keep certain variables in the describe scope, which is error-prone. This is why all such scoped variables that can be used in tests are moved into a context in Zoroaster, and test cases become pure, but more on context-testing later.
So what are we controlling with these first TrapCSS tests? Basically, it's HTML and CSS, and we assert on the output. This means we need 2 input properties, and one output. Masks by default look like the following:[Optional preamble to the whole mask]
## test name
input
/* expected */
output
/**/
## test name2
input
/* property */
optional additional prop with
some controlled value
/**/
/* expected */
output 2
/**/This means we give spec names, can add any number of properties, and pass the expected output for comparison also. The testing framework will then execute the test logic that is written only once, and using string assertion (or deep equal for objects), compare the output to expected. In case of an error, it will be shown in the console and the framework will exit with the status code > 0.
In this case, we can construct the following mask. It's a bit complex for the first ever example of a mask, but bear with me, it's not that complicated.import makeTestSuite from '@zoroaster/mask'
import trapcss from '../../src'
// todo: test [foo="val"], [foo='val'], :not([attr~=value])
const contextFreeUnarySel = makeTestSuite(
'test/result/0-context-free-unary-sel', {
getResults() {
let html, css
if (!this.preamble) {
[html, ...css] = this.input.split('\n')
css = css.join('\n')
} else {
html = this.preamble
css = this.input
}
[,html] = /content: '(.+?)'/.exec(html)
return trapcss({ html, css })
},
mapActual({ css }) {
return css
},
})
export default {
'Context-free, unary selector': contextFreeUnarySel,
}To create a mask, we import the makeTestSuite method from @zoroaster/mask that comes together with Zoroaster. The first argument to this function is a path to the mask result file, or directory with multiple such files, that will be scanned recursively. The second argument is the actual config to the mask, and will include either methods like getResults (most general use case), getReadable, getTransform (if our library returned streams) or fork configuration (to test Node processes). All properties from the mask are available via the this keyword: this.preamble, this.input. We'll organise tests by files, so that a preamble in each file can be used as HTML input, whereas the body of each test will be the CSS string. When we don't write preamble, we'll split the test input by new line to derive HTML and CSS.
We want to extract HTML using the regex: [,html] = /content: '(.+?)'/.exec(html), to be able to receive syntax highlighting in mask results, which will be saved as .scss files. After HTML and CSS strings are ready, we simply pass them to trapcss and return results. Our function is synchronous, but it would also be possible to test async methods by writing async getResults(){}. Using the mapping function mapActual we then return the css property of the whole result, so that it can be compared against the expected one from the mask result. If we wanted to assert on other properties from the result too using JavaScript, we could implement another method called assertResults but we're only interested in testing produced CSS here. This is how our mask results look like:// *: should retain present
html { content: '<div></div>' }
* {a:b;}
/* expected */
*{a:b;}
/**/This is the default mask result for the very first test, without a preamble, but with HTML followed by new line and CSS in the test body. The reason to write html in CSS is to keep syntax highlighting in the whole file, for example if we only gave HTML as a string, we'd get red lines everywhere in the file, as shown below.

Each new tests starts with the comment // characters — a default unless a markdown file is used, in which case it'd be ##. This can also be controlled via the splitRe setting of the mask config.
html { content: '<div></div>' }
// should retain present
div {a:b;}
/* expected */
div{a:b;}
/**/
// should drop absent
span {a:b;}
/* expected */
/**/
// :not - should retain present
:not(span) {a:b;}
/* expected */
:not(span){a:b;}
/**/
// :not - should drop absent
:not(div) {a:b;}
/* expected */
/**/This is the mask result for test suite with the tag testing, where HTML is given at the top of the file (called preamble) to be accessed by each test. We can also duplicate this file and change the div tag to self-closing tag in a single place (preamble), to increase test coverage easily. Where the output of the test is expected to be a 0-length string, we just leave the expected property empty.
html { content: '<div id="a"></div>' }
// should retain present
#a {a:b;}
/* expected */
#a{a:b;}
/**/
// should drop absent
#b {a:b;}
/* expected */
/**/
// :not - should retain present
:not(#b) {a:b;}
/* expected */
:not(#b){a:b;}
/**/
// :not - should drop absent
:not(#a) {a:b;}
/* expected */
/**/These are tests for the ID selector, where we used preamble as HTML input for all tests. We write such html as the content property of the CSS rule, so that the IDE will provide syntax highlighting for the best pleasant developer experience while testing. There are more tests for attribute selectors which you can study in the repository but they all follow the same logic so we skip talking about them here.
To run our tests, there are a number of package.json scripts that can be used: yarn npm run [spec|mask|test] depending on whether we want to run specs (see later section), masks or all. We'll just run yarn npm run mask after having constructed our first mask tests.yarn run v1.13.0
$ yarn t test/mask
$ zoroaster -a test/mask
test/mask
bin
unary
Context-free, unary selector
✓ *: should retain present
#id
✓ should retain present
✓ should drop absent
✓ :not - should retain present
✓ :not - should drop absent
.class
✓ should retain present
✓ should drop absent
✓ :not - should retain present
✓ :not - should drop absent
<tag>
✓ should retain present
✓ should drop absent
✓ :not - should retain present
✓ :not - should drop absent
<tag⁄>
✓ should retain present
✓ should drop absent
✓ :not - should retain present
✓ :not - should drop absent
attr
✓ [attr]: should retain present
✓ [attr]: should drop absent
✓ [attr=value]: should retain present
✓ [attr=value]: should drop absent
✓ [attr*=value]: should retain present
✓ [attr*=value]: should drop absent
✓ [attr^=value]: should retain present
✓ [attr^=value]: should drop absent
✓ [attr$=value]: should retain present
✓ [attr$=value]: should drop absent
✓ [attr~=value]: should retain present
✓ [attr~=value]: should retain present (multiple first)
✓ [attr~=value]: should retain present (multiple second)
✓ [attr~=value]: should drop absent
✓ [attr~=value]: should drop absent (reverse)
:not
✓ [attr]: should retain present
✓ [attr]: should drop absent
✓ [attr=value]: should retain present
✓ [attr=value]: should drop absent
✓ [attr*=value]: should retain present
✓ [attr*=value]: should drop absent
✓ [attr^=value]: should retain present
✓ [attr^=value]: should drop absent
✓ [attr$=value]: should retain present
✓ [attr$=value]: should drop absent
🦅 Executed 42 tests.
Done in 1.85s.Focus In Masks
To focus on a particular test, we can prepend its name with ! in the mask result like so:
// !should retain present
#a {a:b;}
/* expected */
#a{a:b;}
/**/It's also possible to focus on an entire mask, by adding ! to the path of a mask result, or exporting the mask with $ name:
// use ! in mask result path
const contextFreeUnarySel = makeTestSuite(
'!test/result/0-context-free-unary-sel', {
getResults() {},
// ...
})
// named export with $
export const $contextFreeUnarySel = makeTestSuite(
'test/result/0-context-free-unary-sel', {
getResults() {},
// ...
})
// export with $ in object
export default {
'$Context-free, unary selector': contextFreeUnarySel,
}In Zoroaster, test suites are nested objects. For better reporting, we exported the default test suite as an object with the Context-free, unary selector property that contains the test suite generated by the mask. But we could also simply export a variable using a named export, it's just that we won't be able to report the test suite name as a sentence with whitespace and commas.
Interactive Mode
If the test was failing, Zoroaster would use string comparison algorithm to present where the error was in color. Let's imagine we entered our expected value incorrectly:
// !should retain present
#a {a:b;}
/* expected */
.a{a:c;}
/**/The error will be shown using color highlighting in the CLI. Moreover, it's possible to run Zoroaster in interactive mode with the -i flag that will tell the testing framework that we want to interact with it to update mask results in place if errors were found, as demonstrated below.
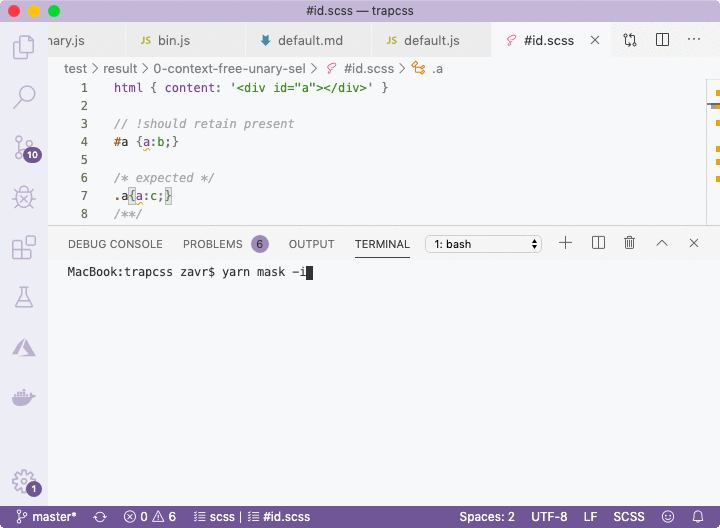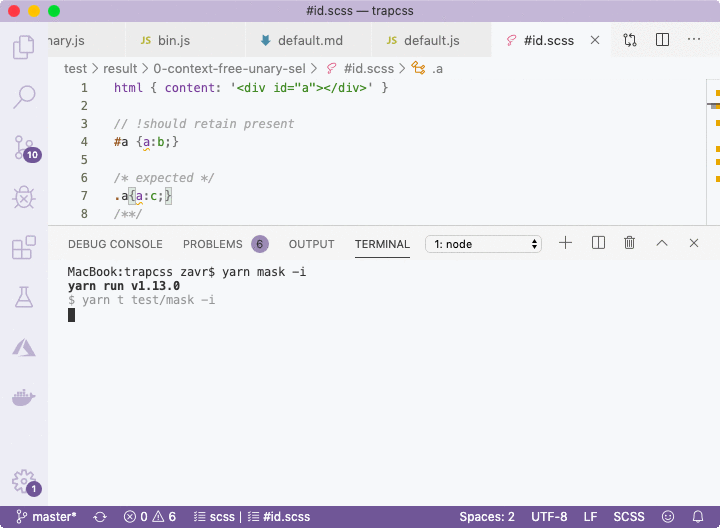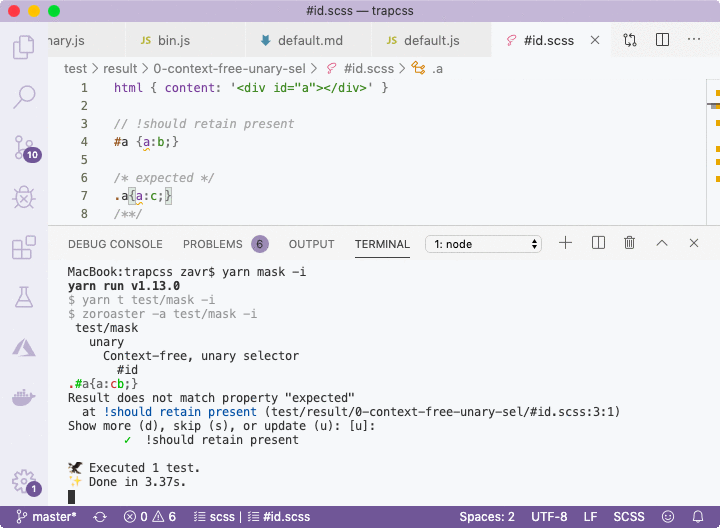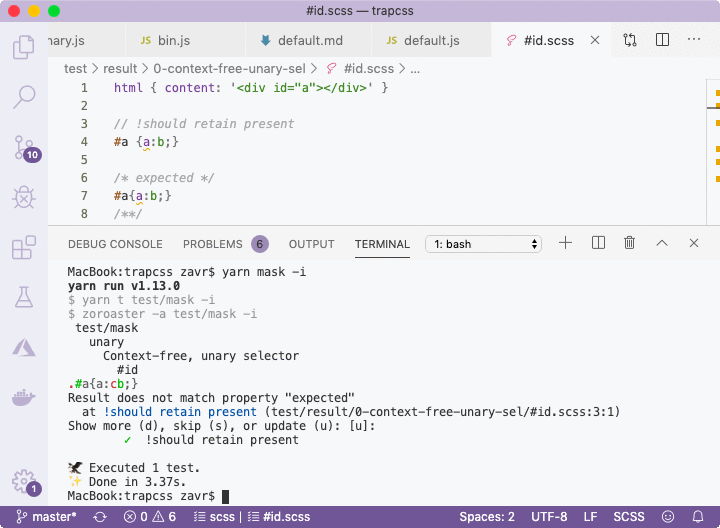
The default option is to update, but more info can be shown if d is pressed, or no updates are made if anything else is passed, in which case the test suite will fail. This is a useful method for quickly drafting new inputs with empty outputs, running interactive mode on them, and populating mask files with outputs, that can then be changed manually or kept as is for more robust regression testing.
More Masks
Let's add some more mask testing.
// test/mask/default.js
import makeTestSuite from '@zoroaster/mask'
import trapcss from '../../src'
const T = makeTestSuite([
'test/result/@keyframes.scss',
'test/result/@font-face.scss'], {
getResults() {
const css = this.preamble
const prepend = this.input
const { css: out } = trapcss({
html: '<div></div>',
css: prepend + css,
})
return out
},
})The makeTestSuite method accepts an array of paths in addition to paths to files and paths to directories. When passing an array, an object will be created where basenames of files from the array are test suite names within the exported object. Above, we just created a T variable, which will be exported as default later. When a test suite has the name "default", its properties are merged up with its parent test suite, so that default test suites' names are never shown during reporting.
The tests for keyframes and font faces have the same structure: they include some page-wide CSS with @keyframes (or @font-face) rules that is placed in the preamble. The test input is a CSS rule that would reference this @keyframes (or @font-face) declaration, so we don't want our library to drop those rules. Therefore, we take the test input and append it to those declarations which are then fed to our trapcss method.div{color: red;}
@keyframes pulse{0%{width:300%;}100%{width:100%;}}
@-webkit-keyframes pulse{0%{width:300%;}100%{width:100%;}}
@keyframes nudge{0%{width:300%;}100%{width:100%;}}
@-webkit-keyframes nudge{0%{width:300%;}100%{width:100%;}}
@keyframes bop{0%{width:300%;}100%{width:100%;}}
@-webkit-keyframes bop{0%{width:300%;}100%{width: 100%;}}
span{color: black;}
// drops all
/* expected */
div{color: red;}
/**/
// drops pulse, nudge
div{animation-name: bop;}
/* expected */
div{animation-name: bop;}div{color: red;}@keyframes bop{0%{width:300%;}100%{width:100%;}}@-webkit-keyframes bop{0%{width:300%;}100%{width: 100%;}}
/**/We can skip adding inputs, if we want to pass an empty string to the test case. This is illustrated with the drops all test case. DropCSS also removes whitespace, therefore our output is placed on a single line. The font face mask results follow the same logic as keyframes. But we also have a special case for font faces:
const fontfaceCustomProps = makeTestSuite(
'test/result/fontface-custom-props.scss', {
getResults() {
const prepend = this.preamble
const css = this.input
const { css: out } = trapcss({
html: '<div></div>',
css: this.doPrepend === false ? css : (prepend + css),
})
return out.replace(css, '')
},
jsProps: ['doPrepend'],
})
T['@font-face (custom props)'] = fontfaceCustomProps
export default TCustom properties means that font faces can be declared with variables. Our root CSS is still taken from preamble, but we add a new property called doPrepend that controls whether it should actually be added to the CSS from input. It allows to put tests in the same result file, but tinker the test logic slightly from test cases themselves (by using properties). Properties could also be written as JSON or JS, in which case we'd need to pass another config item called js[on]Props: ['doPrepend'] that would make the testing framework parse those properties into a JS object. By default, we do prepend the preamble to input CSS, and only when the doPrepend property is explicitly set to false, we don't do it.
Because all test suites generated in this file should be on the same level, but the name of the custom-props test suite had to be written in English with spaces (hence it couldn't be exported as simple variable), we assigned a property to the default object T which is then exported. It's not proper ECMA modules standard since a named export is assigned to a default export which is a function, but behind the scenes exports are transpiled into simple module.exports assignments anyway, so there's no problem with hacks like this.// transpilation example
const T = makeTestSuite()
T['@font-face (custom props)'] = fontfaceCustomProps
// export default T
module.exports = T
// export const keyframes = makeTestSuite()
module.exports.keyframes = keyframesWe run Zoroaster with -a flag that enables ÀLaMode transpilation. Zoroaster is not yet compatible with Node 13's mjs modules (sorry). We'll provide an MNP template setting for native mjs modules by the time Node 14 (LTS) is out, but the transpiler is a 0-dep package anyway.
div{color: red;}:root {--font-family: Foo, 'Bar Baz';}
@font-face {font-family: Foo}
// 1) drops if unused --font-family: should not be confused with font use
div{font-family: 'Open Sans', Fallback, sans-serif;}
/* expected */
div{color: red;}div{font-family: 'Open Sans', Fallback, sans-serif;}
/**/
// 2) retains if used in font-family
div{font-family: var(--font-family);}
/* expected */
div{color: red;}:root{--font-family: Foo, 'Bar Baz';}@font-face{font-family: Foo}div{font-family: var(--font-family);}
/**/
// 3) retains if used - deep resolve
:root {--font: var(--sty) var(--wgt) 1em/var(--lht) var(--fam1), var(--fam2); --sty: italic; --wgt: bold; --lht: var(--hgt)em; --fam1: 'Open Sans'; --fam2: Arial; --hgt: 1.6;}
@font-face {font-family: var(--fam1);}
div {font: var(--font);}
/* doPrepend */
false
/**/
/* expected */
:root{--font: var(--sty) var(--wgt) 1em/var(--lht) var(--fam1), var(--fam2); --sty: italic; --wgt: bold; --lht: var(--hgt)em; --fam1: 'Open Sans'; --fam2: Arial; --hgt: 1.6;}@font-face{font-family: var(--fam1);}div{font: var(--font);}
/**/In the first test, we checked that if a font-face declared as a variable wasn't used, it's declaration and block with declaration of its variable that became empty were dropped. In the second test we verified that the variable block as well as the rule block that uses this variable are kept. Finally, the third test made sure that when the font property references a variable which in turn references another variable, the CSS is retained.
The next test suite is pretty simply, but reads HTML from its own property rather than from the preamble as it will be changed from test to test.export const customProps = makeTestSuite(
'test/result/custom-props.scss', {
getResults() {
const [,html] = /content: '(.+?)'/.exec(this.html)
const { css } = trapcss({
html,
css: this.input,
})
return css
},
})There's actually only one test in this test suite, but the point is that instead of repeating JS logic time and time again, we can simply be adding new test cases by specifying their inputs and outputs. It saves a lot of time and makes us very agile during development — if a bug needs to be fixed, or a feature added, we can go to the mask result, add the input, keep the output empty, generate current output using interactive mode, adjust it to how it should be, run tests, see them fail, then adjust source code to achieve desired behaviour.
// does not confuse BEM -- classes with custom props
:root{--red: #f00;}.a--b:hover{color: var(--red);}.--c{width: 10px;}
/* html */
html { content: '<div class="a--b"></div><div class="--c"></div>' }
/**/
/* expected */
:root{--red: #f00;}.a--b:hover{color: var(--red);}.--c{width: 10px;}
/**/The final test is for our new functionality that allows to preserve alternate comments. We could also write it as a spec, but masks are just as suitable for this task.
export const alternate = makeTestSuite(
'test/result/alternate.scss', {
getResults() {
const { css } = trapcss({
html: '<div/>',
css: this.input,
keepAlternate: true,
})
return css
},
})Original DropCSS also doesn't produce pretty output, which is another reason why I wanted to run it through Stylesheets after its pass. If we were to place output in specs, we'd have to define a string with multiple lines and complex formatting, and assert using string equality, which wouldn't show where strings were different, like masks do with red/green color diffs.
// keeps the alternate comment
div {
text-decoration: underline;
/* @alternate */
text-decoration: underline dotted;
}
/* expected */
div{text-decoration: underline;
/* @alternate */
text-decoration: underline dotted;}
/**/Error Stacks
Please note that if there was a run-time error in algorithms, the report will only show the location in the mask result where the test failed. Imagine that we made an mistake when creating the mask, by referencing the .css mask result property instead of .input, which evaluated to undefined, but our source code expected a string:
export const alternate = makeTestSuite(
'test/result/alternate.scss', {
getResults() {
const { css } = trapcss({
html: '<div/>',
css: this.css,
keepAlternate: true,
})
return css
},
})We'd get the following error in the CLI:
$ zoroaster -a test/mask
test/mask
alternate
✗ !keeps the alternate comment
| Error: Cannot read property 'replace' of undefined
| at !keeps the alternate comment (test/result/alternate.scss:13:1)The error stack has been modified to point to the location of the test in the mask result (alternate.scss:13:1), for convenience of navigation, but it's not a problem with inputs/outputs, but test logic. To fix this, we need to set DEBUG=1 env variable when running tests:
bash-3.2$ DEBUG=1 yarn mask
yarn run v1.13.0
$ yarn t test/mask
$ zoroaster -a test/mask
test/mask
alternate
TypeError: Cannot read property 'replace' of undefined
at parse (/Users/zavr/adc/trapcss/src/css.js:178:13)
at dropcss (/Users/zavr/adc/trapcss/src/index.js:40:16)
at Object.getResults (/Users/zavr/adc/trapcss/test/mask/default.js:53:23)
at /Users/zavr/adc/trapcss/node_modules/@zoroaster/mask/compile/depack.js:688:27
at t.(anonymous function) (/Users/zavr/adc/trapcss/node_modules/@zoroaster/mask/compile/depack.js:789:15)
at bb (/Users/zavr/adc/trapcss/node_modules/zoroaster/depack/bin/zoroaster.js:409:66)
at <anonymous>
✗ !keeps the alternate comment
| Error: Cannot read property 'replace' of undefined
| at !keeps the alternate comment (test/result/alternate.scss:13:1)Now we're given the full stack. As a rule of thumb, whenever you encounter an error that you don't understand in NodeTools, try rerunning the program with DEBUG=1 env variable — our convention is to display full error stacks when the DEBUG is set. This can help fix unknown errors.
Context Testing
Overall, when executing new tests, we get the following report:
$ zoroaster -a test/mask/default.js
test/mask/default.js
@keyframes
✓ drops all
✓ drops pulse, nudge
✓ drops bop
✓ retains nudge
@font-face
✓ retains if used
✓ retains if used (shorthand)
✓ drop if unused
✓ drops if unused (multiple defs)
@font-face (custom props)
✓ drops if unused --font-family: should not be confused with font use
✓ retains if used in font-family
✓ retains if used - deep resolve
✓ drop if unused - deep resolve
customProps
✓ does not confuse BEM -- classes with custom props
alternate
div{text-decoration: underline;⏎
/* @alternate */⏎
text-decoration: underline dotted;}
✗ keeps the alternate comment
| Error: 'div{text-decoration: underline;text-decoration: underline dotted;}' == 'div{text-decoration: underline;\n /* @alternate */\n text-decoration: underline dotted;}'
| at keeps the alternate comment (test/result/alternate.scss:1:1)
test/mask/default.js > alternate > keeps the alternate comment
Error: 'div{text-decoration: underline;text-decoration: underline dotted;}' == 'div{text-decoration: underline;\n /* @alternate */\n text-decoration: underline dotted;}'
at keeps the alternate comment (test/result/alternate.scss:1:1)
🦅 Executed 14 tests: 1 error.The last error is due to the fact that the new functionality has not been implemented. But it's OK since it's in spirit of test-driven development: we added a test first, before the source code. With mask testing, the TDD methodology is easily embraced as test cases are very easy to add by simply providing new data. Instead of wasting our time on setting up test routines in JS, we can try to come up with as many use cases via masks.
DropCSS contains more tests, but for the purposes of the tutorial we don't need to look at them further, except for the integration test.describe('Bulma-Bootstrap-Surveillance', () => {
let html, css;
describe('stress test', () => {
it('should run', function() {
let {css: out} = dropcss({
html: fs.readFileSync(__dirname + '/../bench/stress/input/surveillance.html', 'utf8'),
css: fs.readFileSync(__dirname + '/../bench/stress/input/bootstrap.min.css', 'utf8') +
fs.readFileSync(__dirname + '/../bench/stress/input/bulma.min.css', 'utf8'),
});
assert.equal(vkbeautify(out), fs.readFileSync(__dirname + '/../bench/stress/output/dropcss.pretty.css', 'utf8'));
});
});
});We're going to write it as a spec, that will return the result of the call to trapcss function, since Zoroaster supports snapshots automatically by recording returned values in the test/snapshot directory, and then comparing all future returned values with the saved one. This is what our spec looks like:
// test/spec/default.js
import ServiceContext from 'zoroaster'
import Context from '../context'
import trapcss from '../../src'
/** @type {Object.<string, (c: Context, z: ServiceContext)>} */
const T = {
context: [Context, ServiceContext],
'bench stress test'({ bootstrap, readFile, fixture }, { snapshotExtension }) {
snapshotExtension('css')
const bt = readFile(bootstrap)
const bulma = readFile(fixture`bulma.min.css`)
const css = bt + bulma
const res = trapcss({
css,
html: readFile(fixture`surveillance.html`),
})
return res.css
},
}
export default TZoroaster is a context-testing framework. Contexts are a way to unload test utilities, such as methods for reading files, from tests suites, by putting them in a single place called a context, and make them accessible via destructuring from each test case. In addition, instances of test contexts can implement _init and _destroy methods so it's an alternative to beforeEach and afterEach hooks for functional style programming, since each test case is now a pure function that receives testing API from arguments rather than scope. This allows to organise test suites by files instead of cramming them all into the same file because we relied on some complex set up routine that we don't want to copy/paste in each test suite file. In DropCSS we only relied on simple methods like readFileSync but in more complex software we might have more sophisticated API, e.g., in koa/session:
/* 750 lines of tests */
function App(options) {
const app = new Koa();
app.keys = [ 'a', 'b' ];
options = options || {};
options.ContextStore = ContextStore;
options.genid = ctx => {
const sid = Date.now() + '_suffix';
ctx.state.sid = sid;
return sid;
};
app.use(session(options, app));
return app;
}The App function is used by each single test, the test suite file is large because they are all tied to this testing API. There could be a separate file that exported this function, like it's done in Koa (test/helpers/context.js):
'use strict';
const Stream = require('stream');
const Koa = require('../..');
module.exports = (req, res, app) => {
const socket = new Stream.Duplex();
req = Object.assign({ headers: {}, socket }, Stream.Readable.prototype, req);
res = Object.assign({ _headers: {}, socket }, Stream.Writable.prototype, res);
req.socket.remoteAddress = req.socket.remoteAddress || '127.0.0.1';
app = app || new Koa();
res.getHeader = k => res._headers[k.toLowerCase()];
res.setHeader = (k, v) => res._headers[k.toLowerCase()] = v;
res.removeHeader = (k, v) => delete res._headers[k.toLowerCase()];
return app.createContext(req, res);
};
module.exports.request = (req, res, app) => module.exports(req, res, app).request;
module.exports.response = (req, res, app) => module.exports(req, res, app).response;Koa then requires those helpers whenever it needs to in test suites:
const context = require('../helpers/context');
const Koa = require('../..');
describe('ctx.redirect(url)', () => {
it('should redirect to the given url', () => {
const ctx = context();
ctx.redirect('http://google.com');
assert.equal(ctx.response.header.location, 'http://google.com');
assert.equal(ctx.status, 302);
});
it('should escape the url', () => {
const ctx = context();
let url = '<script>';
ctx.header.accept = 'text/html';
ctx.redirect(url);
url = escape(url);
assert.equal(ctx.response.header['content-type'], 'text/html; charset=utf-8');
assert.equal(ctx.body, `Redirecting to <a href="${url}">${url}</a>.`);
});
})
function escape(html){
return String(html)
.replace(/&/g, '&')
.replace(/"/g, '"')
.replace(/</g, '<')
.replace(/>/g, '>');
}Again, those are the simplest examples when the helpers don't take part in set up routines, for example starting a mock server. If they were, each test would be tied up to the test suite file's scope which would force us to place all test in the same file which is not very convenient for navigation and developer freedom. The previous example also adds the escape function at the bottom of the file, to be used by specs in there. But what if it was needed in other test suites, too? It would have to be put in the helpers/context, and that's exactly what Contexts are in Zoroaster — an official place for your testing utilities (we didn't see Koa's code before coming up with the name, it's an accident that their context is called in the same fashion as a testing context).
This is a snippet from Goa's (our compiled Koa fork) context:import Cookies from '@contexts/http/cookies'
import { Duplex, Readable, Writable } from 'stream'
import Koa from '../../src'
export default class Context extends Cookies {
/**
* A mock context.
* @param {http.IncomingMessage} [req]
* @param {http.ServerResponse} [res]
* @param {Koa} [app]
*/
makeContext(req, res, app = new Koa()) {
const socket = new Duplex()
req = Object.assign({ headers: {}, socket }, Readable.prototype, req)
res = Object.assign({ socket }, Writable.prototype, res)
const _headers = {}
req.socket.remoteAddress = req.socket.remoteAddress || '127.0.0.1'
res.getHeader = k => _headers[k.toLowerCase()]
res.getHeaders = () => _headers
res.setHeader = (k, v) => _headers[k.toLowerCase()] = v
res.removeHeader = (k) => delete _headers[k.toLowerCase()]
return app.createContext(req, res)
}
/**
* Returns an instance of a mock context.
*/
get ctx() {
return this.makeContext()
}
/**
* Escapes HTML entities for &, ", < and >.
* @param {string} html
*/
escape(html){
return `${html}`
.replace(/&/g, '&')
.replace(/"/g, '"')
.replace(/</g, '<')
.replace(/>/g, '>')
}
/**
* Pause runtime.
* @param {number} time
*/
sleep(time){
return new Promise(resolve => setTimeout(resolve, time))
}
}Our context extends the @contexts/http/cookies class, that initialises a web-server when startPlain method is called and returns a tester instance for making requests to it and asserting on the results, supertest style. There's also a possibility set PersistentContexts that act as global before and after hooks, but practice shows that it takes only a few ms to start a server therefore it's OK to use a normal context. When integration-testing larger apps and needing to run background processes, like headless Chrome, we would definitely be able to use a persistent context. Persistent contexts are actually the best feature to illustrate advantages of context-testing, as they allow to move the setup and teardown logic into separate files, instead of rewriting it over and over again in the before and after hooks, or cramming all test suites in the same file.
{
context: Context,
async 'sets status code'({ app, startPlain }) {
app.use((ctx) => {
ctx.status = 204
})
await startPlain(app.callback())
.get('/')
.assert(204)
},
}The additional advantage lies in the fact that we implement our own testing API on top of existing one. It is then from the context that specs access testing utilities, and what is more, we receive full JSDoc support for our context's API. Any number of contexts can be passed to test suites.
Context-testing decouples test cases from the testing infrastructure and allows to treat each test as a pure function that receives its inputs from arguments instead of file scope.
Of course, test cases are not 100% pure as we're still importing src within the test suite, but it's OK since we still want to be practical. It would be possible to import src from context, and make it available for access by test cases, in which case they will be 100% pure. This could let us to do cool stuff like hosting spec functions completely independently from the source code (e.g., as lambdas for longer integration testing routines that could then be run in parallel to complete a test suite in a matter of seconds), and even plugging in different versions of source code into tests. But these are more advanced concepts from Quality Assurance theory. For now it's enough to say that context-testing from NodeTools formalises the helper pattern and enables JSDoc access to testing API.
This is our context for that spec:import { join } from 'path'
import { readFileSync } from 'fs'
/**
* A testing context for the package.
*/
export default class Context {
/**
* A tagged template that returns the relative path
* to the fixture.
* @param {string} file
* @example
* fixture`input.txt` // -> test/fixture/input.txt
*/
fixture(file) {
const f = file.raw[0]
return join('test/fixture', f)
}
/**
* Path to bootstrap.
*/
get bootstrap() {
return this.fixture`bootstrap.min.css`
}
/**
* Read the file from the fs.
* @param {string} path The path to read.
*/
readFile(path) {
return readFileSync(path, 'utf8')
}
}The testing interface and its implementation provide a method for synchronously reading files, a method to resolve paths to fixtures from the fixture directory, as well as the bootstrap property that resolves to the bootstrap path. We'll need to place some fixtures, such as bulma.min.css and surveillance.html into the fixtures folder so that they can be used in test. If we ever wanted to reuse bootstrap fixture, we'd simply destructure its path from the context, and read it if necessary. But if our package could, for example, accept a path to a CSS file instead of CSS as string, we'd already have everything we needed to test such feature. This makes us extremely productive and our QA experience very pleasant.
The spec will read bulma and bootstrap, put them together, and use HTML from the prepared html file to pass to TrapCSS. The result is returned by the test, and when run for the first time, Zoroaster asks us if we want to save the snapshot. After it was saved, all further executions of the test will compare the output to the recorded one.
will read bulma and bootstrap, put them together, and use HTML from the prepared html file to pass to TrapCSS. The result is returned by the test, and when run for the first time, Zoroaster asks us if we want to save the snapshot. After it was saved, all further executions of the test will compare the output to the recorded one.
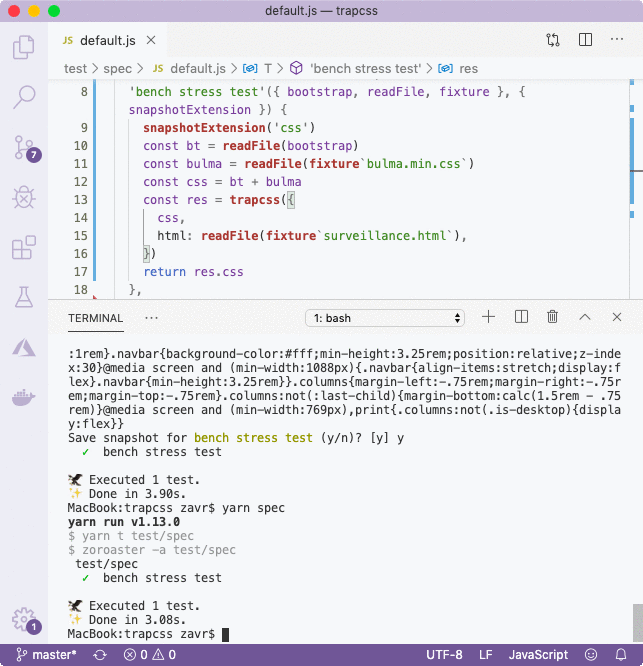
We also used a service context from Zoroaster as our second context to change the format of the saved file to CSS. Instead of recording snapshots in JSON files, we write them to files with the extensions of the data format that they contain. This allows us to visually inspect our snapshots with syntax highlighting, which improves our DevX too.
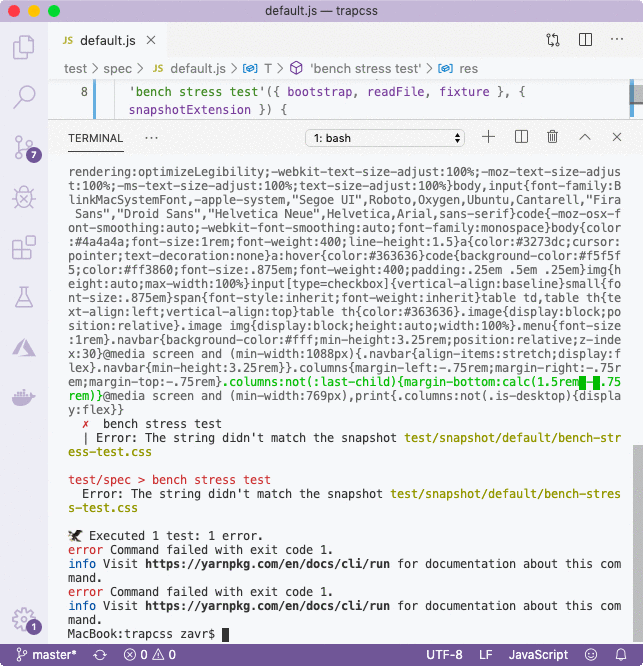
If at some point we changed our source code, and the output of the program changed, we'd be notified of it by Zoroaster with green/red highlighting on string differences too. We could then run tests in interactive mode as yarn npm test -- -i (same as forks) to update snapshots from the CLI.
In sum, there are following folders found in the test dir:- context: our helper methods implemented as a class for JSDoc access to methods.
- fixture: any external files required for testing.
- mask: test suites created with makeTestSuite from @zoroaster/mask package that are constructed dynamically from input-output pairs.
- result: test cases for masks that provide inputs and expected outputs, stored in any convenient file format that provides appropriate syntax highlighting.
- snapshot: results returned by specs are saved here.
- spec: atomic test cases nested within folders and thus organised by tests suites that make use of contexts.

Implementation
Now that we've transferred the source code rewritten as ECMA modules, documented it with initial examples, designed the API via types in XML, and unit-tested our library with masks and snapshots, we can move on to discussing more serious concepts such as compilation, wikis and binary functionality in the next part of this tutorial. But first, let's take a selfie actually implement the logic that we needed for our package, that is, the comment preservation feature.
// src/css.js
function parse(css) {
// strip comments (for now)
css = css.replace(COMMENTS, '');
return tokenize(css);
}We make a very simple change that allows to preserve the keepAlternate comment. After the change is made, we run yarn npm test to validate that all tests now pass, since we've already created a test case for /* @alternate */ in masks in TDD fashion.
export function parse(css, keepAlternate) {
// strip comments (for now)
css = css.replace(COMMENTS, keepAlternate ? (m) => {
if (/^\s*\/\* @alternate \*\/\s*$/.test(m)) return m
return ''
} : '')
return tokenize(css)
}Whenever the second new attribute, keepAlternate is passed, instead of stripping all comments that it finds, our method will test if the comment is the alternate block comment using a regex, and keep it if required. Although this could potentially break the parser in places, because we had tests, we don't need to be afraid of side effects introduced by this change. The author of the original package mentioned that he doesn't like the fact that such feature would have negative impact on speed, however there's no impact at all if the second argument is actually not truthy. If my advice can be of any value, please don't concern yourself with micro-optimisations and imaginary split millisecond gains at times when humanity is starting to use quantum computers.
If you need a feature, implement it regardless in what way without bothering with performance because our machines are made for computation so give them something to do. A new feature can branch out in unexpected ways and help you explore new ideas. But it's also true for when trying to overcome somebody's resistance to change, or bugs. Keep positive and treat any obstacle as a personal opportunity to create something amazing. Focus on yourself first and foremost, as you're programming for your own pleasure/business goals and don't need anyone else to tell you what is acceptable and not. You're in charge of your programs. NodeTools helps you remain the master of your work. TrapCSS 2: Advanced NodeToolsLoading sharing buttons...

Comments